Hands-Object Interaction

Hands allow humans to interact with, and use, physical objects, but capturing hand motion is a challenging computer-vision task. To tackle this, we learn a statistical model of the human hand [![]() ], called MANO, that is trained using many 3D scans of human hands and represents the 3D shape variation across a human population. We combine MANO with the SMPL body model and FLAME face model to obtain the expressive SMPL-X model, which allows us to reconstruct realistic bodies and hands using our 4D scanner, mocap data, or monocular video.
], called MANO, that is trained using many 3D scans of human hands and represents the 3D shape variation across a human population. We combine MANO with the SMPL body model and FLAME face model to obtain the expressive SMPL-X model, which allows us to reconstruct realistic bodies and hands using our 4D scanner, mocap data, or monocular video.
MANO can be fit to noisy input data to reconstruct hands and/or objects [![]()
![]() ] from a monocular RGB-D or multiview RGB sequence. Interacting motion also helps to recover the unknown kinematic skeleton of objects [
] from a monocular RGB-D or multiview RGB sequence. Interacting motion also helps to recover the unknown kinematic skeleton of objects [![]() ].
].
To directly regress hands and objects, we developed ObMan [![]() ], a deep-learning model that integrates MANO as a network layer, to estimate the 3D hand and object meshes from an RGB image of grasping. For training data, we use MANO and ShapeNet objects to generate synthetic images of hand-object grasps. ObMan's joint hand-object reconstruction allows the network to encourage contact and discourage interpenetration.
], a deep-learning model that integrates MANO as a network layer, to estimate the 3D hand and object meshes from an RGB image of grasping. For training data, we use MANO and ShapeNet objects to generate synthetic images of hand-object grasps. ObMan's joint hand-object reconstruction allows the network to encourage contact and discourage interpenetration.
Hand-object distance is central to grasping. To model this, we learn a Grasping Field [![]() ] that characterizes every point in a 3D space by the signed distances to the surface of the hand and the object. The hand, the object, and the contact area are represented by implicit surfaces in a common space. The Grasping Field is parameterized with a deep neural network trained on ObMan's synthetic data.
] that characterizes every point in a 3D space by the signed distances to the surface of the hand and the object. The hand, the object, and the contact area are represented by implicit surfaces in a common space. The Grasping Field is parameterized with a deep neural network trained on ObMan's synthetic data.
ObMan's dataset contains hand grasps synthesized by robotics software. However, real human grasps look more varied and natural. Moreover, humans use not only their hands, but also use the body and face during interactions. We therefore capture GRAB [![]() ], a dataset of real whole-body human grasps of objects. We use a high-end MoCap system, capture 10 subjects interacting with 51 objects, and reconstruct 3D SMPL-X [
], a dataset of real whole-body human grasps of objects. We use a high-end MoCap system, capture 10 subjects interacting with 51 objects, and reconstruct 3D SMPL-X [![]() ] human meshes interacting with 3D object meshes, including dynamic poses and in-hand manipulation. We use GRAB to train GrabNet, a deep network that generates 3D hand grasps for unseen 3D objects.
] human meshes interacting with 3D object meshes, including dynamic poses and in-hand manipulation. We use GRAB to train GrabNet, a deep network that generates 3D hand grasps for unseen 3D objects.
Videos
Datasets
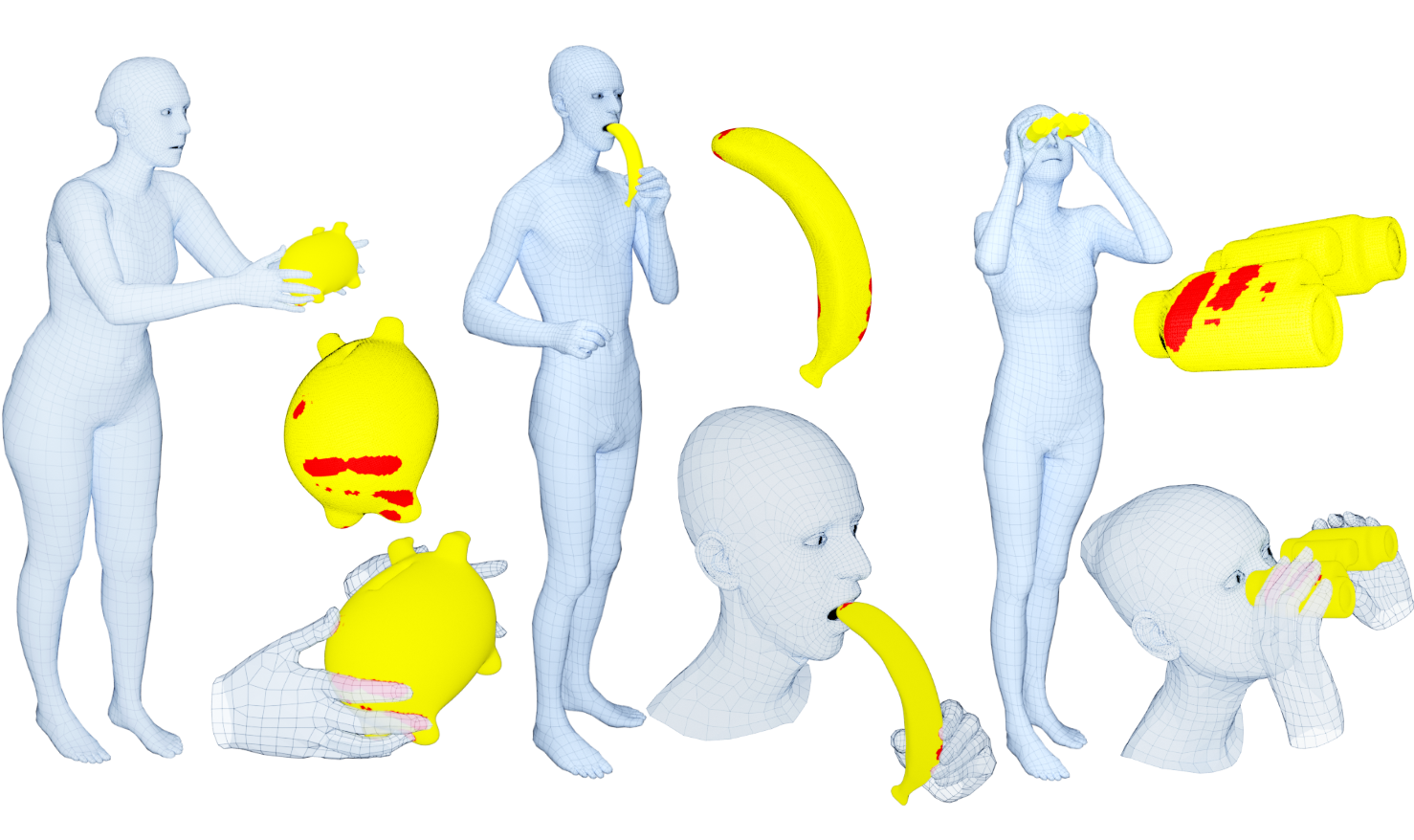 GRAB (ECCV 2020) dataset (link)
GRAB (ECCV 2020) dataset (link)
A dataset of 3D whole-body grasps during human-object interaction.
The dataset contains 1.622.459 frames in total. Each one has:
- an expressive 3D SMPL-X human mesh (shaped and posed),
- a 3D rigid object mesh (posed), and
- contact annotations (wherever applicable).
 ObMan (CVPR 2019) dataset (link)
ObMan (CVPR 2019) dataset (link)
Synthetic dataset with
- RGB rendered images
- full annotated ground truth (meshes, model parameters, etc) for
- hand &
- object

SIGGRAPH-Asia 2017 (TOG) models/dataset (link)
Models & Alignments & Scans, for:
- hand-only (MANO)
- body+hand (SMPL+H)
 ECCVw 2016 dataset (link)
ECCVw 2016 dataset (link)
RGB-D dataset of an object under manipulation.
The dataset also contains input 3D template meshes
for each object and output articulated models.

IJCV 2016 dataset (link)
Annotated RGB-D + multicamera-RGB dataset of one or two hands
interacting with each other and/or with a rigid or an articulated object

ICCV 2015 dataset (link)
RGB-D dataset of a hand rotating a rigid object for 3d scanning

GCPR 2014 dataset (link)
Annotated RGB-D dataset of one or two hands interacting with each other

GCPR 2013 dataset (link)
Synthetic dataset of two hands interacting with each other
Members











Publications