
































Our research uses Computer Vision to learn digital humans that can perceive, learn, and act in virtual 3D worlds. This involves capturing the shape, appearance, and motion of real people as well as their interactions with each other and the 3D scene using monocular video. We leverage this to learn generative models of people and their behavior and evaluate these models by synthesizing realistic looking humans behaving in virtual worlds.
This work combines Computer Vision, Machine Learning, and Computer Graphics.
Director

Michael Black
Emeritus / Acting DirectorAdmin Team

Melanie Feldhofer
Department Manager
Nicole Overbaugh
Office CoordinatorPerceiving Systems Highlights


Michael J. Black elected to the U.S. National Academy of Engineering


Contact-Aware Refinement of Human Pose Pseudo-Ground Truth via Bioimpedance Sensing

Im2Haircut: Single-view Strand-based Hair Reconstruction for Human Avatars



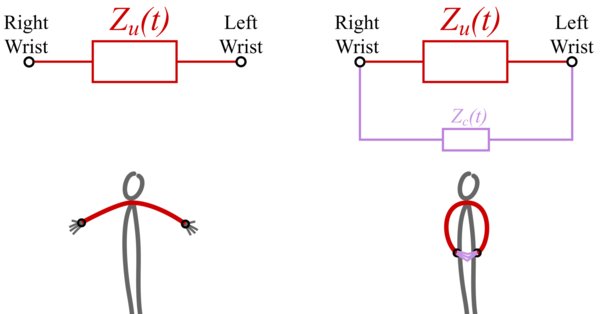
Wrist-to-Wrist Bioimpedance Can Reliably Detect Discrete Self-Touch
 IEEE Transactions on Instrumentation and Measurement
IEEE Transactions on Instrumentation and Measurement





PuzzleAvatar: Assembling 3D Avatars from Personal Albums






HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video

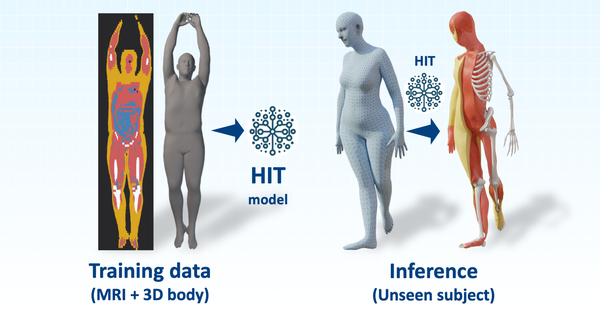
HIT: Estimating Internal Human Implicit Tissues from the Body Surface

WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion


SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes

