Datasets for understanding humans and animals

Perceiving Systems has a long history of creating and supporting datasets that advance our research and that of the broader research community. In computer vision today, high-quality data at scale is often the key to success. Over the reporting period, we have produced novel datasets that are driving the field.
Synthetic data: We made a major investment in synthetic data with the creation of BEDLAM [![]() ], a realistic synthetic dataset containing monocular RGB videos with ground-truth 3D bodies in SMPL-X format. BEDLAM includes a diversity of body shapes, motions, skin tones, hair, clothing, scenes, lighting, and camera motions. We show, for the first time, that using BEDLAM one can train a state-of-the-art human pose and shape regressor using no real data. This is a game changer for the field. BEDLAM is in wide use and we are working hard on a major upgrade to drive the field in new directions.
], a realistic synthetic dataset containing monocular RGB videos with ground-truth 3D bodies in SMPL-X format. BEDLAM includes a diversity of body shapes, motions, skin tones, hair, clothing, scenes, lighting, and camera motions. We show, for the first time, that using BEDLAM one can train a state-of-the-art human pose and shape regressor using no real data. This is a game changer for the field. BEDLAM is in wide use and we are working hard on a major upgrade to drive the field in new directions.
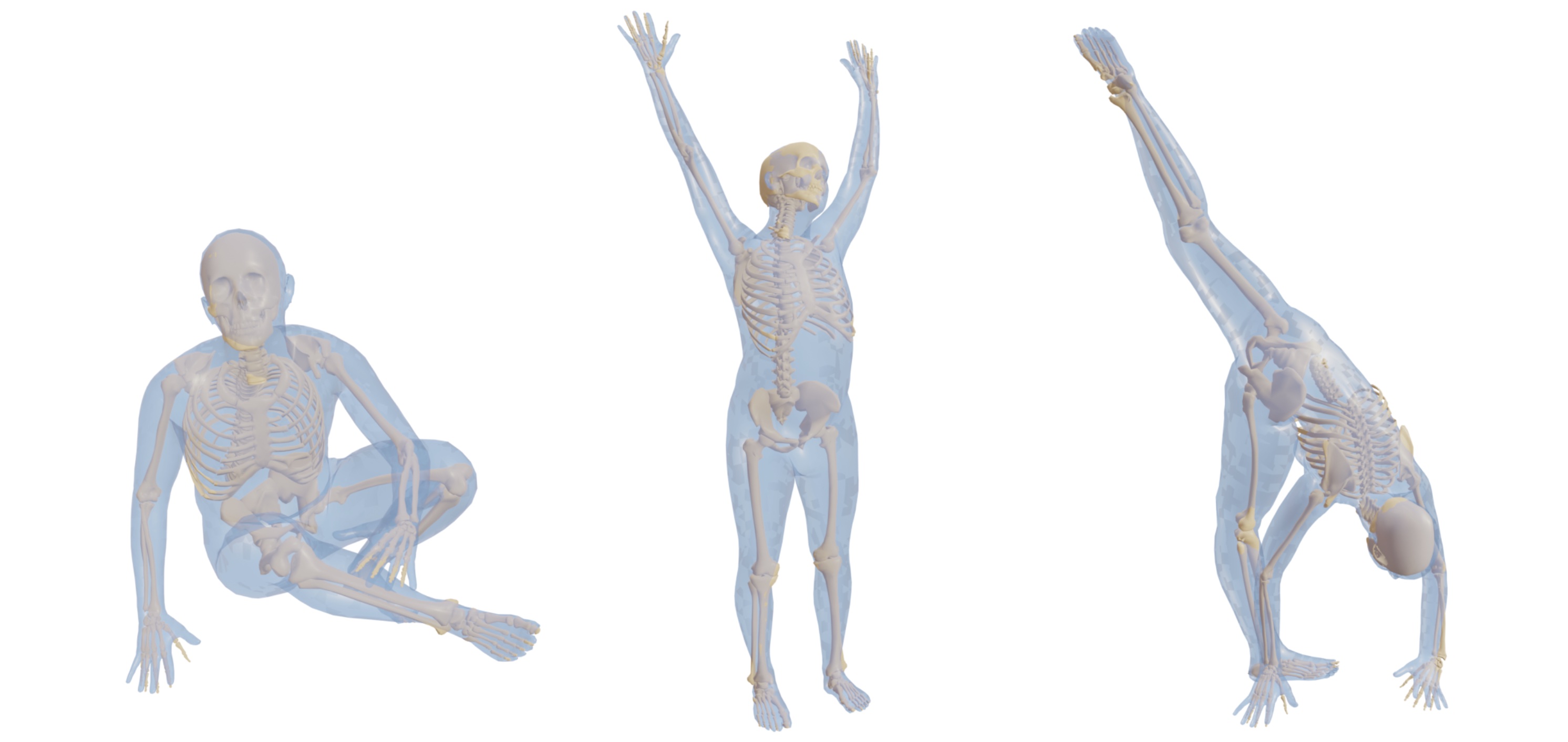
Captured data: We observe that existing 3D human regressors tend to fail for extreme poses. This is due to a lack of training data that push the limits of the human body. To address this, we captured MOYO [![]() ], a dataset of yoga poses with precise 3D ground truth. MOYO also includes pressure data captured with a pressure mat.
], a dataset of yoga poses with precise 3D ground truth. MOYO also includes pressure data captured with a pressure mat.
Contact datasets: Human-object and human-scene contact is central to human behavior. To help capture and model contact, we created unique datasets that we made available to the community. RICH [![]() ] contains detailed 3D scans of indoor and outdoor scenes, the accurate 3D pose and shape of people, and detailed 3D contact labels. INTERCAP [
] contains detailed 3D scans of indoor and outdoor scenes, the accurate 3D pose and shape of people, and detailed 3D contact labels. INTERCAP [![]() ] and ARCTIC [
] and ARCTIC [![]() ] focus on human-object interaction in more controlled settings. ARCTIC, is the first dataset of 3D humans manipulating articulated objects. We track the 3D objects and the full human body precisely, while also capturing video from both egocentric and alocentric views. We have also developed multiple datasets that focus on contact in internet images. HOT [
] focus on human-object interaction in more controlled settings. ARCTIC, is the first dataset of 3D humans manipulating articulated objects. We track the 3D objects and the full human body precisely, while also capturing video from both egocentric and alocentric views. We have also developed multiple datasets that focus on contact in internet images. HOT [![]() ] provides 2D image regions where humans are contacting objects, while DAMON [
] provides 2D image regions where humans are contacting objects, while DAMON [![]() ] uses a novel labeling tool to collect dense 3D vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. To study human-human contact, we created the Flickr Fits dataset [
] uses a novel labeling tool to collect dense 3D vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. To study human-human contact, we created the Flickr Fits dataset [![]() ] by fitting SMPL-X to images of humans in contact for which we have labeled ground truth contact.
] by fitting SMPL-X to images of humans in contact for which we have labeled ground truth contact.
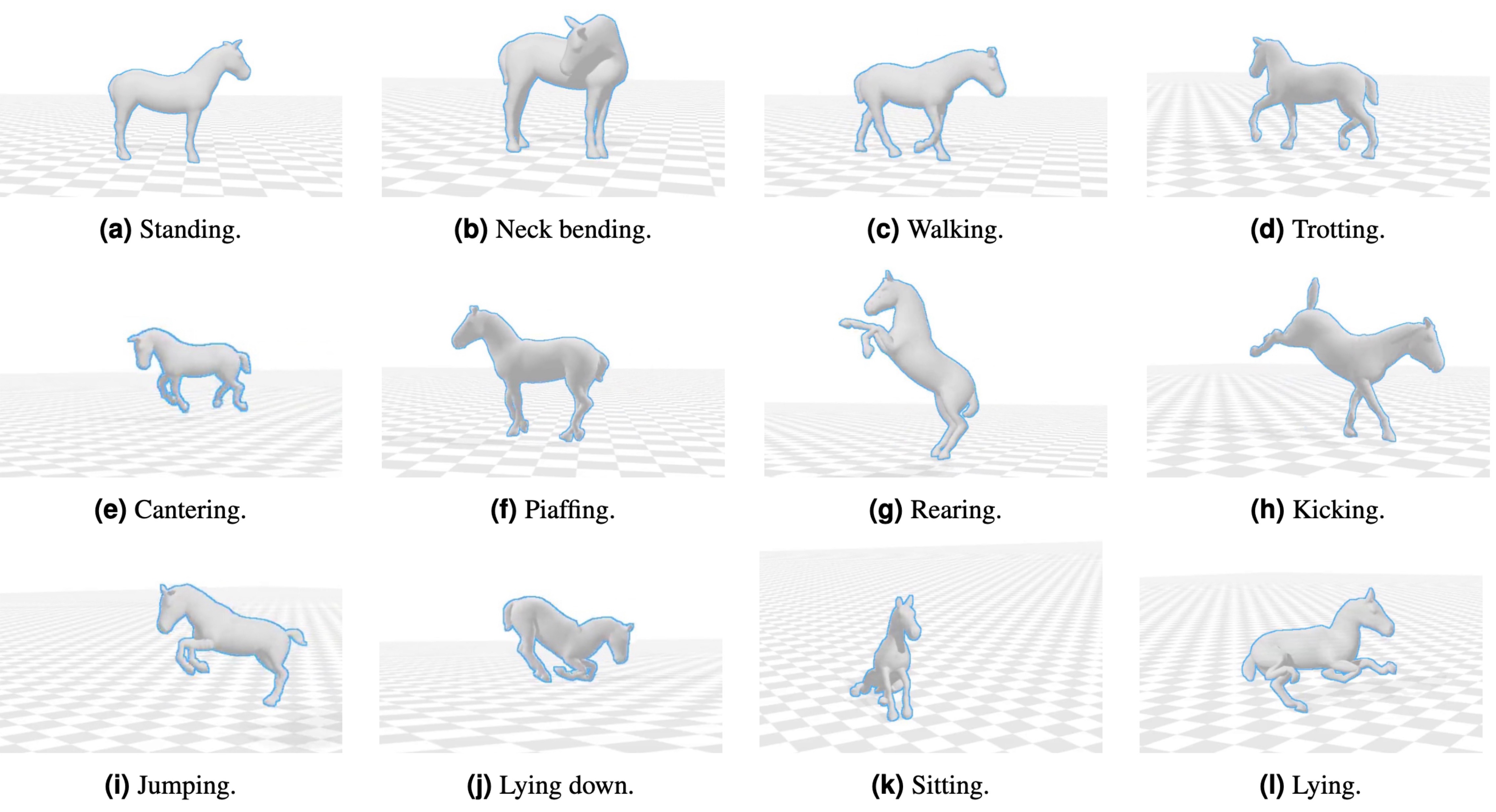
Beyond humans: We have long worked on animals as well as humans. For example, we built a 4D horse scanner with collaborators in Sweden and released the most extensive dataset of 3D horse scans (VAREN [![]() ]) and motion data (PFERD [
]) and motion data (PFERD [![]() ]) ever captured.
]) ever captured.