Implicit Representations
While triangulated meshes are the dominant 3D representation in computer graphics, their fixed topology makes them ill-suited to modeling humans in clothing, where the topology varies between garments and over time. They also do not directly model distances between surfaces, which are central to human-scene interaction.
Recent work on deep implicit functions provides us with an alternative in which shape is defined using a deep neural network that defines either the occupancy at every point in a 3D volume or the signed distance to the object surface. The surface can then be extracted as the zero level set of this function.
Implicit functions are flexible in both resolution and topology, making them suitable to model clothed humans. A key step is to extend the notion of linear blend skinning from the surface of the mesh to the full 3D volume. Learning a 3D human entails learning skinning fields that allow posing and un-posing the body such that pose-dependent shape changes can be learned in a canonical pose space.
We explore these ideas in three recent papers: LEAP [![]() ], SNARF [
], SNARF [![]() ], and SCANimate [
], and SCANimate [![]() ]. SCANimate learns an implicit model directly from raw 3D scans and is trained with a cycle-consistency loss as self-supervision.
]. SCANimate learns an implicit model directly from raw 3D scans and is trained with a cycle-consistency loss as self-supervision.
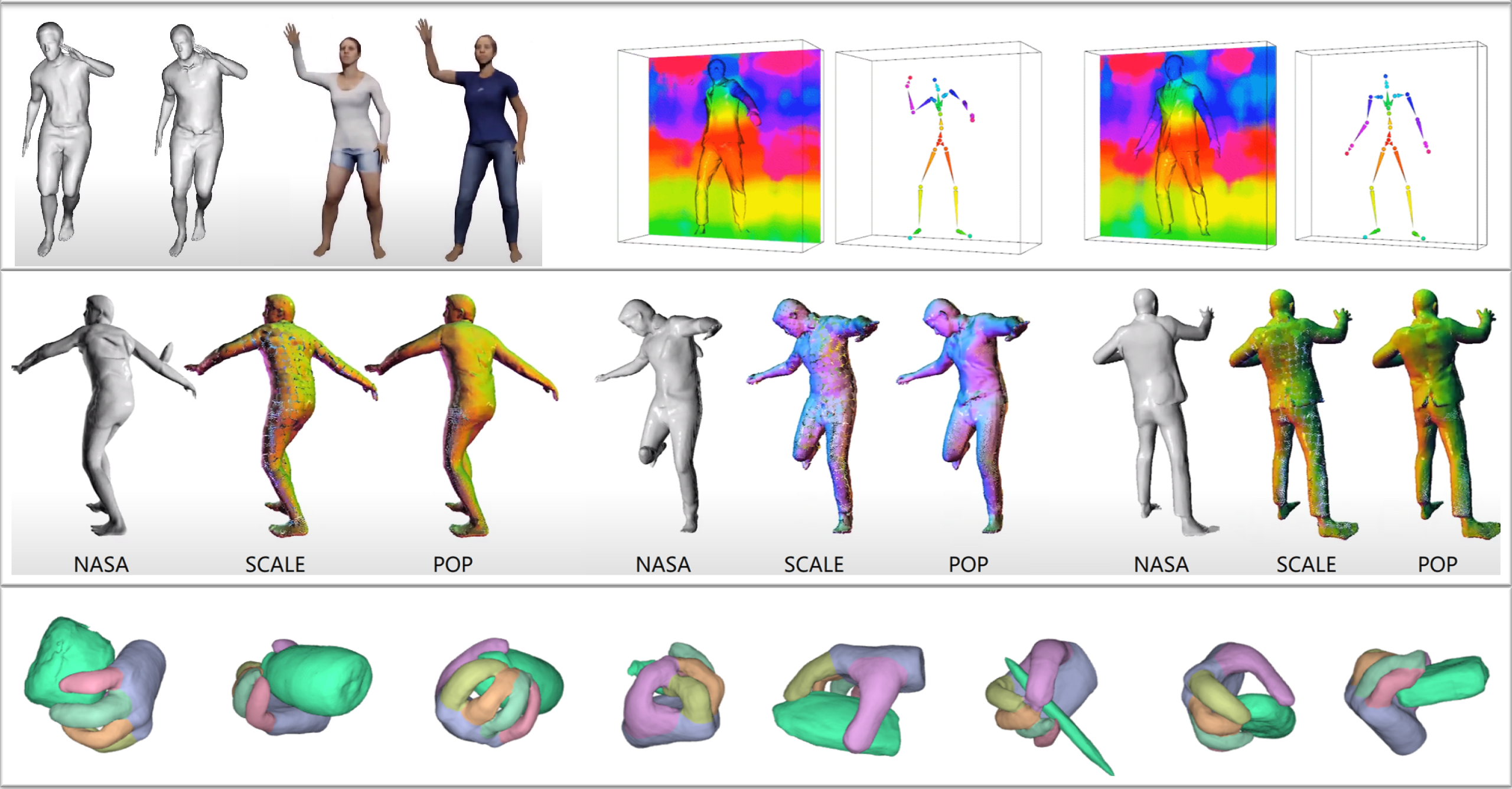
Current implicit representations are slow for inference. To address this, we propose two novel point cloud representations (SCALE [![]() ] and POP [
] and POP [![]() ]), where the surface is implicitly defined by the points. While SCALE models a single clothed person, POP is trained to model a wide variety of clothing.
]), where the surface is implicitly defined by the points. While SCALE models a single clothed person, POP is trained to model a wide variety of clothing.
We also extend implicit representations to model hand-object interaction. For each point in space, if we know its signed distance to the hand and the object, we can infer the interaction between them. If both are zero, then the hand is touching the object; both positive, no contact; both negative, interpenetration occurs. Specifically, we learn a GraspingField [![]() ] from which we can generate various grasping hand poses for given objects.
] from which we can generate various grasping hand poses for given objects.
Members










Publications