Human Pose, Shape and Action
3D Pose from Images
2D Pose from Images
Beyond Motion Capture
Action and Behavior
Body Perception
Body Applications
Pose and Motion Priors
Clothing Models (2011-2015)
Reflectance Filtering
Learning on Manifolds
Markerless Animal Motion Capture
Multi-Camera Capture
2D Pose from Optical Flow
Body Perception
Neural Prosthetics and Decoding
Part-based Body Models
Intrinsic Depth
Lie Bodies
Layers, Time and Segmentation
Understanding Action Recognition (JHMDB)
Intrinsic Video
Intrinsic Images
Action Recognition with Tracking
Neural Control of Grasping
Flowing Puppets
Faces
Deformable Structures
Model-based Anthropometry
Modeling 3D Human Breathing
Optical flow in the LGN
FlowCap
Smooth Loops from Unconstrained Video
PCA Flow
Efficient and Scalable Inference
Motion Blur in Layers
Facade Segmentation
Smooth Metric Learning
Robust PCA
3D Recognition
Object Detection
MPI Sintel Flow
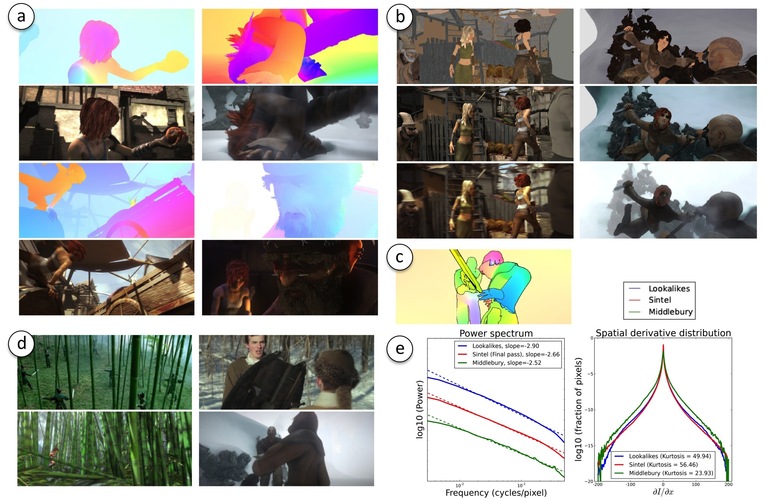
Ground truth datasets have spurred innovation in several fields of computer vision, since they provide objective evaluation criteria and encourage competition in the community. However, such datasets have a limited lifespan, at the end of which new methods perform only marginally better, and/or overfit to the data in the evaluation set. Additionally, in the case of optical flow, ground truth is difficult to measure in real scenes with natural motion. As a result, optical flow data sets are restricted in terms of size, complexity, and diversity, making optical flow algorithms difficult to train and test on realistic data.
The goal of this project was to create a new optical flow data set derived from the open source 3D animated short film Sintel. From this movie, we extracted 35 sequences displaying different environments, characters/objects, and actions. The data set consisting of these scenes exhibits important features not present in the popular Middlebury flow evaluation data set: long sequences, large motions, nonrigidly moving objects, specular reflections, motion blur, defocus blur, and atmospheric effects. To facilitate training, we released the ground truth optical flow for 23 of these sequences. The ground truth optical flow for the remaining 12 sequences is withheld for evaluation purposes.
While the effects mentioned increase the realism of our dataset compared to others previously used in the field of optical flow, the data set is nevertheless synthetic, and thus, at least perceptually, not ''real''. To validate the use of synthetic data, we collected real-life "lookalike" video clips from five semantic categories corresponding to our sequences: Fighting in snow, Bamboo forest, Indoor, Market chase, and Mountain.
We compared the sequences in our data set to these lookalike clips and, as a further comparison, to clips from the popular Middlebury benchmark, using two sets of criteria: first-order image statistics and first-order optical flow statistics. For image statistics, we computed the brightness intensity histograms, power spectra, and gradient magnitude distributions. For the optical flow statistics, ground truth optical flow does not exist for the lookalike videos. We therefore used an existing optical flow (Classic+NL) method as a proxy for the real optical flow, and computed speed and direction distributions and spatial derivatives for these proxy optical flow fields.
For both the image and the optical flow statistics, we found that the Sintel clips are, in all cases, between the lookalike sequences and Middlebury. Considering that both consist of real, photographic images, we conclude that, at least in terms of first-order statistics, Sintel is sufficiently similar to real video to serve as an optical flow benchmark.
Using the test set, we evaluated a number of optical flow estimation algorithms, and, as expected, found the Sintel data set to be much more challenging in general than the Middlebury data set. Specifically, we identified two conditions under which current algorithms for optical flow estimation fail. The first condition is a high velocity. In regions with velocities above 40 pixels per frame the endpoint error is approximately 45x higher than in regions with velocities between 0 and 10 pixels per frame.
The second condition is whether a region is unmatched, i.e. only visible in one of two adjacent frames. In those regions, the errors are on average 8x higher than in regions that are visible in both frames.
From these two failure conditions, we conclude that optical flow estimation can be significantly improved by better modeling large motion, and by reasoning about the structure of the world to be able to model and make educated guesses about motion in occluded and unmatched regions.
The dataset, as well as all results and more information can be downloaded from http://www.mpi-sintel.de.
Evaluation
The evaluation website is here http://www.mpi-sintel.de.
Video
Members




Publications