The estimation of 3D human pose from 2D joint locations is central to many vision problems involving the analysis of people in images and video. To address the fact that the problem is inherently ill posed, many methods impose a prior over human poses. Unfortunately these priors admit invalid poses because they do not model how joint-limits vary with pose. Here we make two key contributions. First, we collected a motion capture dataset that explores a wide range of human poses. From this we learn a pose-dependent model of joint limits that forms our prior. The dataset and the prior will be made publicly available. Second, we define a general parameterization of body pose and a new, multistage, method to estimate 3D pose from 2D joint locations that uses an over-complete dictionary of human poses. Our method shows good generalization while avoiding impossible poses. We quantitatively compare our method with recent work and show state-of-the-art results on 2D to 3D pose estimation using the CMU mocap dataset. We also show superior results on manual annotations on real images and automatic part-based detections on the Leeds sports pose dataset.
Dynamic Bayesian networks such as Hidden Markov
Models (HMMs) are successfully used as probabilistic models
for human motion. The use of hidden variables makes
them expressive models, but inference is only approximate
and requires procedures such as particle filters or Markov
chain Monte Carlo methods. In this work we propose to instead
use simple Markov models that only model observed
quantities. We retain a highly expressive dynamic model by
using interactions that are nonlinear and non-parametric.
A presentation of our approach in terms of latent variables
shows logarithmic growth for the computation of exact loglikelihoods
in the number of latent states. We validate
our model on human motion capture data and demonstrate
state-of-the-art performance on action recognition and motion
completion tasks.
We advocate the inference of qualitative information about 3D human
pose, called posebits, from images. Posebits represent boolean
geometric relationships between body parts
(e.g., left-leg in front of right-leg or hands close to each other).
The advantages of posebits as a mid-level representation are 1)
for many tasks of interest, such qualitative
pose information may be sufficient (e.g. , semantic image retrieval),
2) it is relatively easy to annotate large image corpora with posebits, as
it simply requires answers to yes/no questions; and 3) they help
resolve challenging pose ambiguities and therefore
facilitate the difficult talk of image-based 3D pose estimation.
We introduce posebits, a posebit database, a method for selecting useful
posebits for pose estimation and a structural SVM model for posebit inference.
Experiments show the use of posebits for semantic image
retrieval and for improving 3D pose estimation.
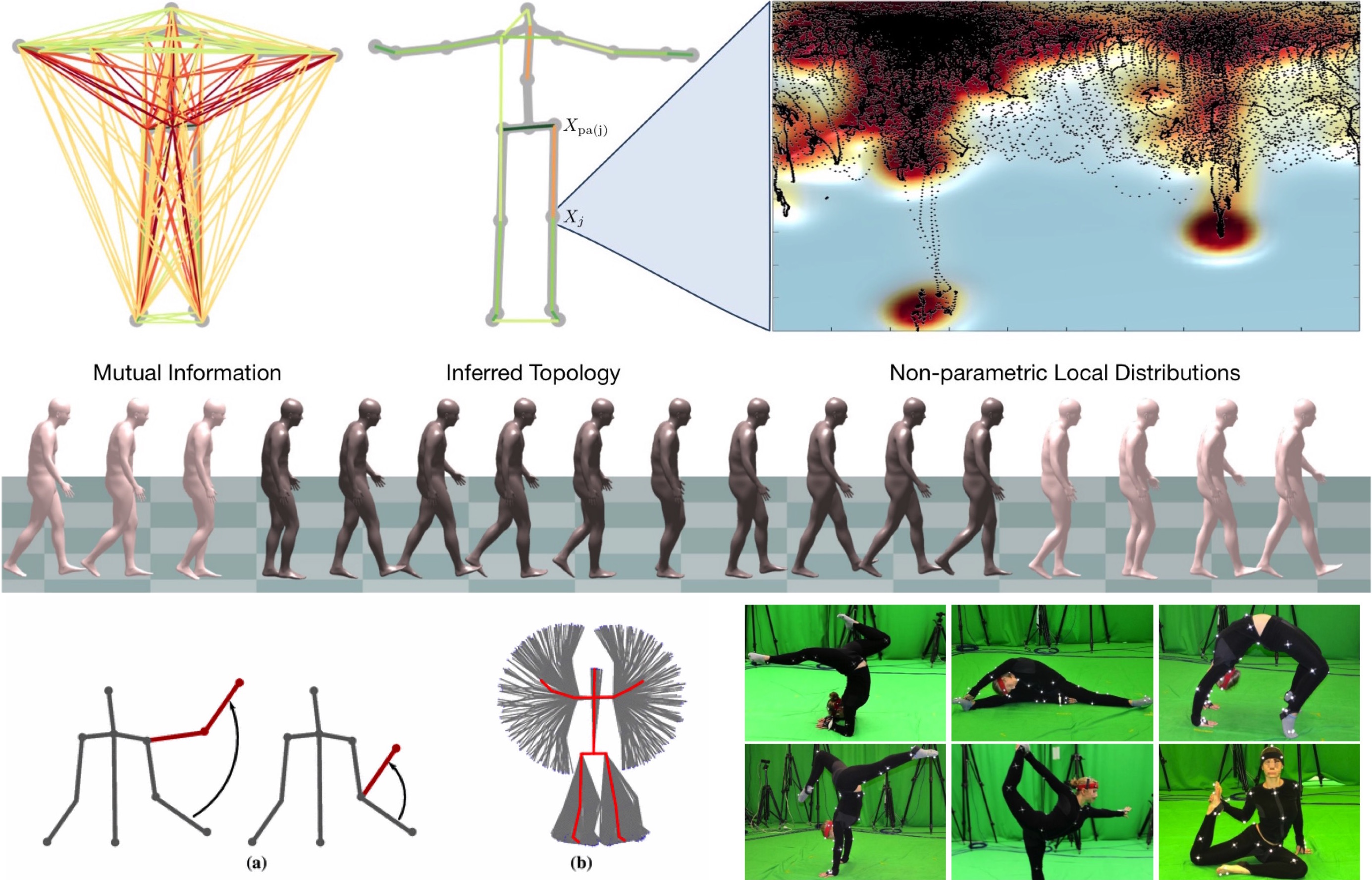
Having a sensible prior of human pose is a vital ingredient for many computer vision applications, including tracking and pose estimation. While the application of global non-parametric approaches and parametric models has led to some success, finding the right balance in terms of flexibility and tractability, as well as estimating model parameters from data has turned out to be challenging. In this work, we introduce a sparse Bayesian network model of human pose that is non-parametric with respect to the estimation of both its graph structure and its local distributions. We describe an efficient sampling scheme for our model and show its tractability for the computation of exact log-likelihoods. We empirically validate our approach on the Human 3.6M dataset and demonstrate superior performance to global models and parametric networks. We further illustrate our model's ability to represent and compose poses not present in the training set (compositionality) and describe a speed-accuracy trade-off that allows realtime scoring of poses.