Neural Rendering
Conventional graphics pipelines take a 3D model like SMPL, apply texture and material properties, light it, and render it as an image. Without expensive artist involvement, this results in unrealistic images that fall into the "uncanny valley". To address this, we develop neural rendering methods that keep the 3D body model but replace the rendering pipeline with neural networks. This approach keeps the flexibility of parametric models while producing realistic looking images without artist intervention.
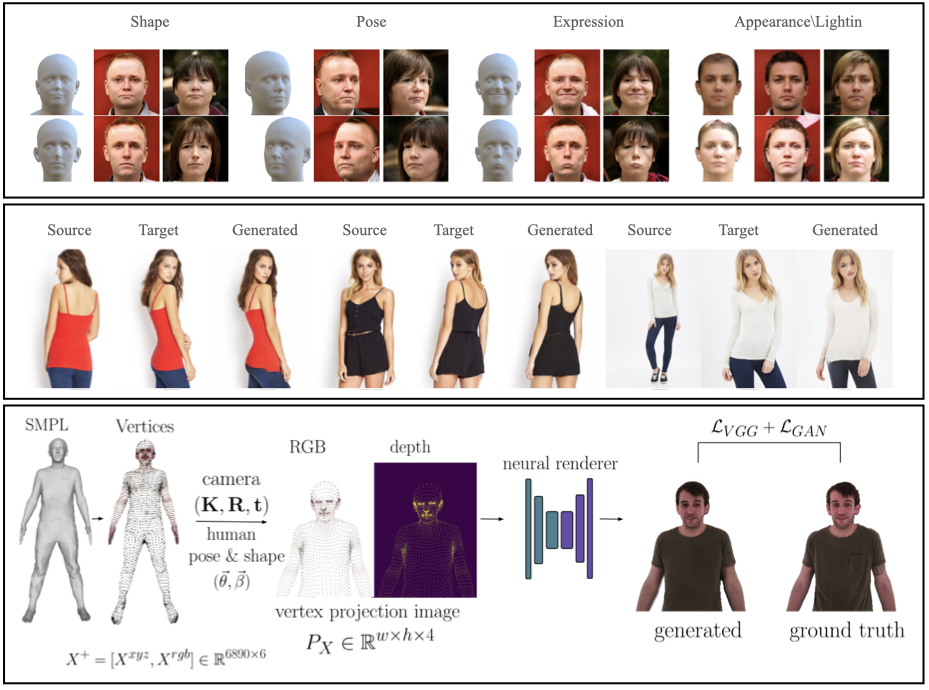
GIF [![]() ] generates realistic images of faces, by conditioning StyleGAN2 on the FLAME face model [
] generates realistic images of faces, by conditioning StyleGAN2 on the FLAME face model [![]() ]. Given FLAME parameters for shape, pose, expressions, plus parameters for appearance, lighting, and an additional style vector, GIF outputs photo-realistic face images.
]. Given FLAME parameters for shape, pose, expressions, plus parameters for appearance, lighting, and an additional style vector, GIF outputs photo-realistic face images.
To generate images of people with realistic hair and clothing, we train SMPLpix [![]() ] to transform a sparse set of 3D mesh vertices and their RGB values into photorealistic images. The 3D mesh vertices are controllable with the pose and shape parameters of SMPL.
] to transform a sparse set of 3D mesh vertices and their RGB values into photorealistic images. The 3D mesh vertices are controllable with the pose and shape parameters of SMPL.
SPICE [![]() ] takes a different approach and synthesizes an image of a person in a novel pose given a source image of the person and a target pose. In contrast to typical approaches that require paired training data, SPICE uses only unpaired data. This is enabled by a novel cycle-GAN training method that exploits information about the 3D SMPL body.
] takes a different approach and synthesizes an image of a person in a novel pose given a source image of the person and a target pose. In contrast to typical approaches that require paired training data, SPICE uses only unpaired data. This is enabled by a novel cycle-GAN training method that exploits information about the 3D SMPL body.
The combination of parametric 3D models with neural rendering enables realistic human rendering with intuitive animation controls.
Members










Publications