Markers to Avatars
Marker-based motion capture (mocap) is the "gold standard" for capturing human motion for animation and biomechanics. Unfortunately, the amount and quality of existing mocap data is small, limiting its use for deep learning. We address this with two key innovations: MoSh [![]() ] and SOMA [
] and SOMA [![]() ], which we use this to create a large dataset of human motions (AMASS [
], which we use this to create a large dataset of human motions (AMASS [![]() ]) with fine-grained action labels (BABEL [
]) with fine-grained action labels (BABEL [![]() ]).
]).
Traditional mocap can produce lifeless and unnatural animations. We argue that this is the result of “indirecting” through a skeleton. In standard mocap, visible 3D markers on the body surface are used to infer the unobserved skeleton in a process called "solving". The skeleton is used to animate a 3D model. While typical protocols place markers on parts of the body that move as rigidly as possible, soft-tissue motion always affects surface marker motion. Since non-rigid motions of surface markers are treated as noise, subtle information about body motion is lost.
MoSh (for Motion and Shape capture) replaces the skeleton with a 3D parametric body model. MoSh simultaneously estimates mocap marker locations on the SMPL body, estimates the body shape, and recovers the articulated body pose. By allowing soft-tissue deformations (DMPL) that vary over time, MoSh achieves high realism.
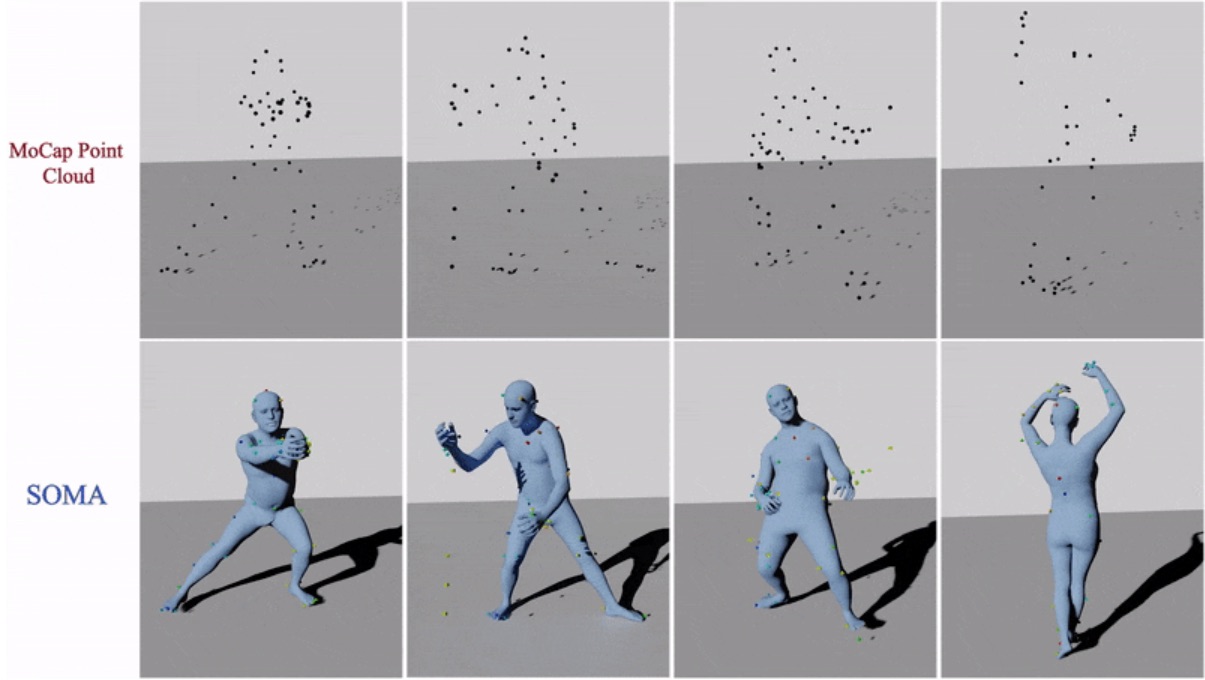
Mocap is also costly because human intervention is need to "clean" and "label" the capture data, which contains noise and missing markers. With SOMA we automate this process. Given a raw, noisy, and incomplete mocap point cloud, SOMA uses a stacked transformer architecture and a normalization layer to assign captured 3D points to markers on the body. The automatically labelled data is then fit with MoSh.
Using these techniques, we maintain the growing AMASS dataset, which converts many disparate datasets into a single unified SMPL-based representation. We have also built the BABEL dataset by acquiring fine-grained action labels for the motions in AMASS. The size of these datasets opens up human motion to deep learning architectures.
Data
Several related datasets and code repositories are available on-line for scientific purposes:
- MoSh http://mosh.is.tue.mpg.de
- SOMA https://soma.is.tue.mpg.de/
- GRAB https://grab.is.tue.mpg.de/
- AMASS and MoSh++ https://amass.is.tue.mpg.de/
- BABEL https://babel.is.tue.mpg.de/
Members




Publications