Inferring Actions
Human behavior can be described at multiple levels. At the lowest level, we observe the 3D pose of the body over time. Poses can be organized into primitives that capture coordinated activity of different body parts. These further form more complex actions. At the most abstract level, behavior can be described semantically in terms of actions and goals.
The BABEL dataset [![]() ] contains labels of actions being performed by subjects in mocap sequences from AMASS [
] contains labels of actions being performed by subjects in mocap sequences from AMASS [![]() ]. BABEL is larger and more complex than existing 3D action recognition datasets, making the action recognition task challenging. BABEL has a long-tailed action distribution, significant intra-class variance, and frequently, multiple actions are performed simultaneously. These characteristics are similar to real-world data, suggesting that BABEL can drive progress in the field.
]. BABEL is larger and more complex than existing 3D action recognition datasets, making the action recognition task challenging. BABEL has a long-tailed action distribution, significant intra-class variance, and frequently, multiple actions are performed simultaneously. These characteristics are similar to real-world data, suggesting that BABEL can drive progress in the field.
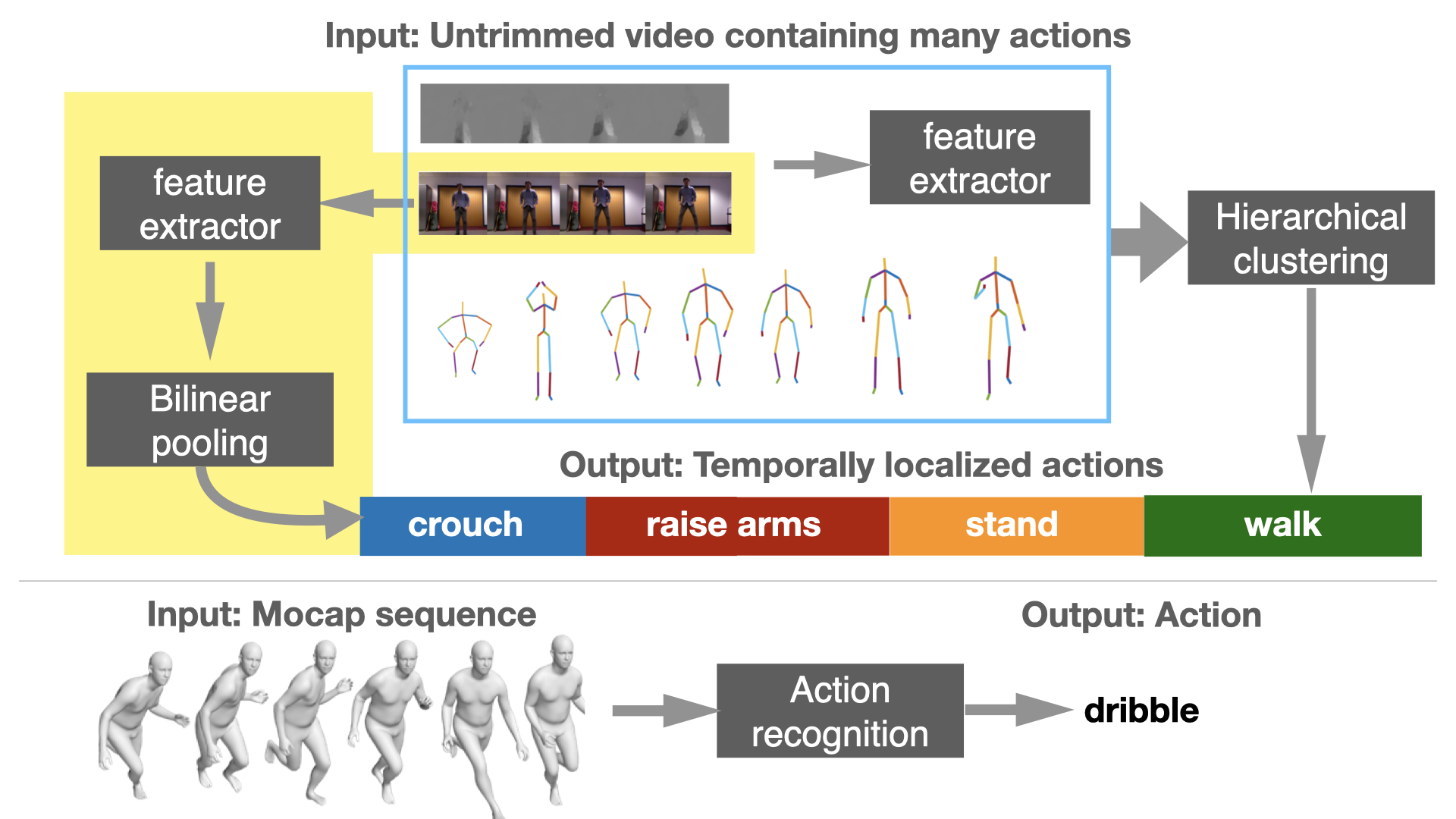
Human movements typically involve different successive actions. In addition to asking what actions are occurring, Temporal Action Localization (TAL) asks when these actions occur; i.e., the start and end of each action in the video.
Prior methods addressing TAL lose important information while aggregating features across successive frames. We develop a novel, learnable bilinear pooling operation to aggregate features that retains fine-grained temporal information [![]() ]. Experiments demonstrate superior performance to prior work on various datasets.
]. Experiments demonstrate superior performance to prior work on various datasets.
Humans can readily differentiate biological motion from non-biological motion without training, even with sparse visual cues like moving dots. In this spirit, we perform behavior analysis at a low-level using a novel dynamic clustering algorithm [![]() ]. Low-level visual cues are aggregated to high-level action patterns, and are utilized for the TAL task.
]. Low-level visual cues are aggregated to high-level action patterns, and are utilized for the TAL task.
Members







Publications