Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Object-centric Self-supervised Reinforcement Learning
Self-exploration of Behavior
Causal Reasoning in RL
Equation Learner for Extrapolation and Control
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Combinatorial Optimization as a Layer / Blackbox Differentiation
Object-centric Self-supervised Reinforcement Learning
Symbolic Regression and Equation Learning
Representation Learning
Stepsize adaptation for stochastic optimization
Probabilistic Neural Networks
Learning with 3D rotations: A hitchhiker’s guide to SO(3)
Equation Learner for Extrapolation and Control
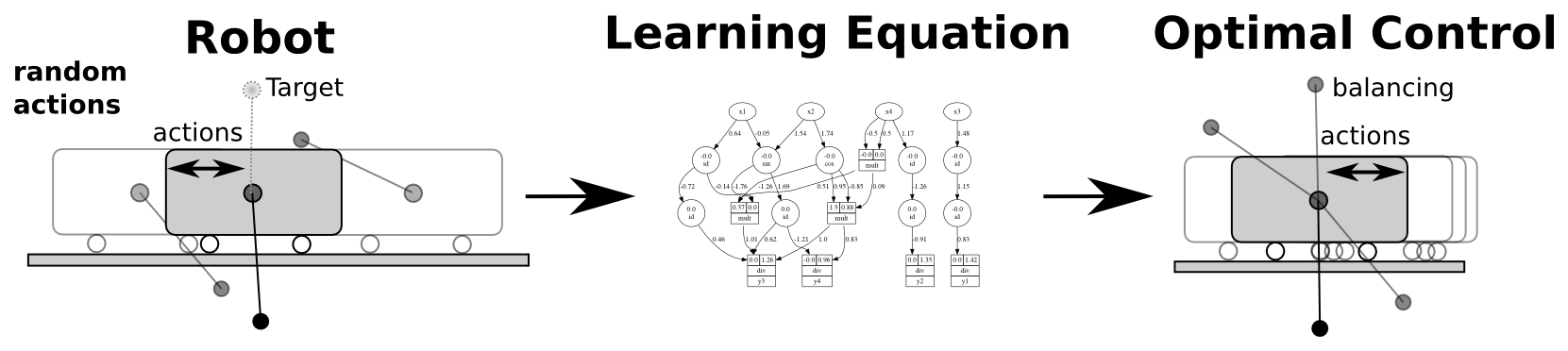
Intelligent systems today, including physical robots, are capable of amazing feats compared to their early predecessors. However, much of the planning and control relies on the accurate identification of the robotic system, often in the form of known physics equations derived by experienced engineers. In the case when the system model is unknown, various function approximations have been used in the context of model-based reinforcement learning. There is a typical trade-off between the explicability and model capacity when applying function approximation, e.g., deep neural networks may model complex system dynamics but are hard to interpret and optimize. Typically, control and planning tasks require much higher accuracy compared to regular machine learning tasks. In addition, it naturally occurs that unseen parts of the state space are visited. So we wish to address the problem of learning models that are highly accurate and also able to extrapolate.
Instead of resorting to black-box function approximation we designed a system to identify the system equation from a limited data range using a gradient-based neural network training[![]() ]. In this way, we solve a symbolic regression problem using a continuous optimization method. The crucial aspect of the method is to find the simplest solution that still explains the data well - implementing Occam's razor.
]. In this way, we solve a symbolic regression problem using a continuous optimization method. The crucial aspect of the method is to find the simplest solution that still explains the data well - implementing Occam's razor.
The identified equations are suitable for extrapolation to unseen domains which we demonstrate using several synthetic and real-world systems. Most importantly we show how to use these learned equations to obtain a highly efficient learning algorithm for control and planning. In our first experiment, a cart-pendulum system learns to swing up from scratch after two random rollouts. Ongoing work is to improve the efficiency and applicability of the method and applying it to challenging robotic systems.
- Slides (pdf) (from a presentation in Edinburgh 2019)
- Poster (pdf) (@ICML)
- Video (youtube)
Members



Publications