Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Causal Reasoning in RL
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Goal-conditioned Offline Planning
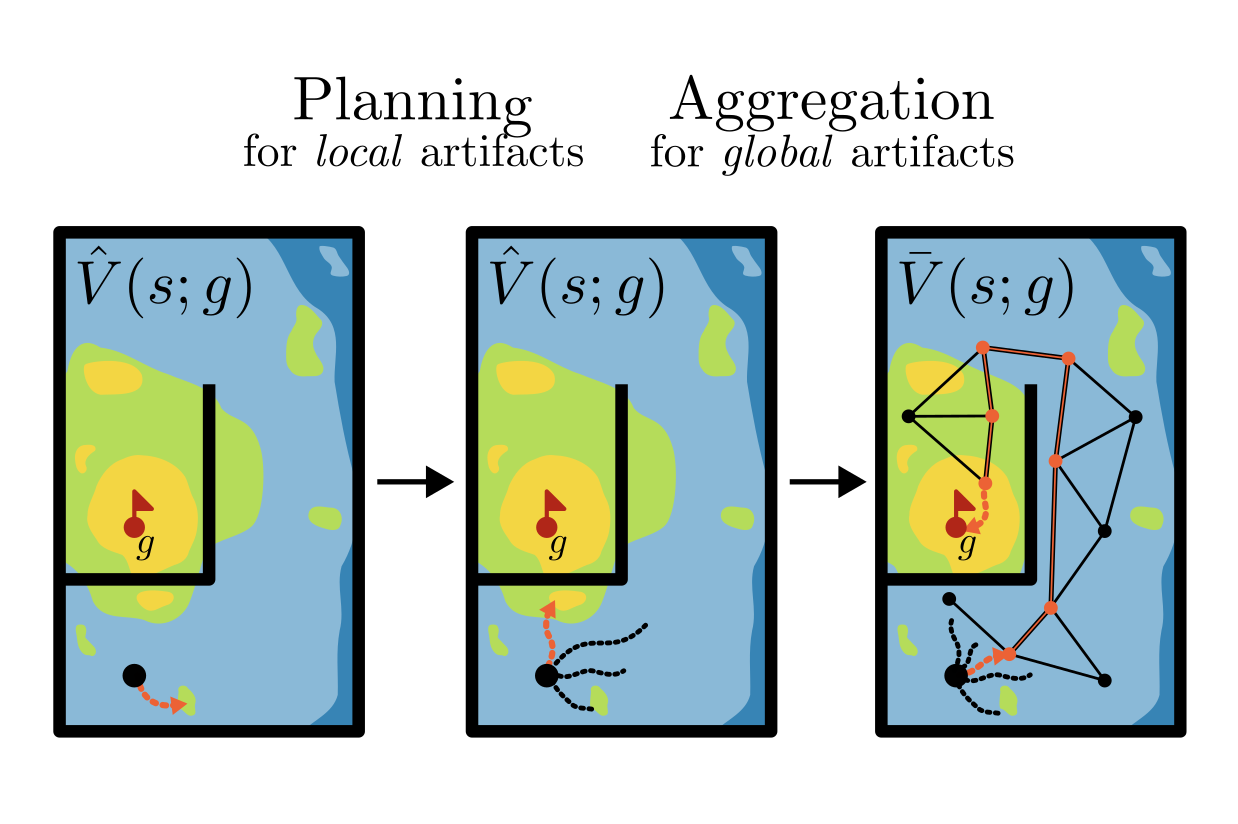
Curiosity has established itself as a powerful exploration strategy in deep reinforcement learning. We consider the challenge of extracting flexible, goal-conditioned behavior from the products of such unsupervised exploration techniques, without any additional environment interaction. An object of central importance to this function is a value function, encoding “temporal distance” between any given state and goals. By analyzing the geometry of optimal goal-conditioned value functions, we highlight estimation artifacts in learned values. In order to mitigate their occurrence, we propose to combine model-based planning over learned value landscapes with a graph-based value aggregation scheme. We show how this combination can correct both local and global artifacts, obtaining significant improvements in zero-shot goal-reaching performance across diverse simulated environments.
Members


Publications