Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Causal Reasoning in RL
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Model-based Reinforcement Learning and Planning
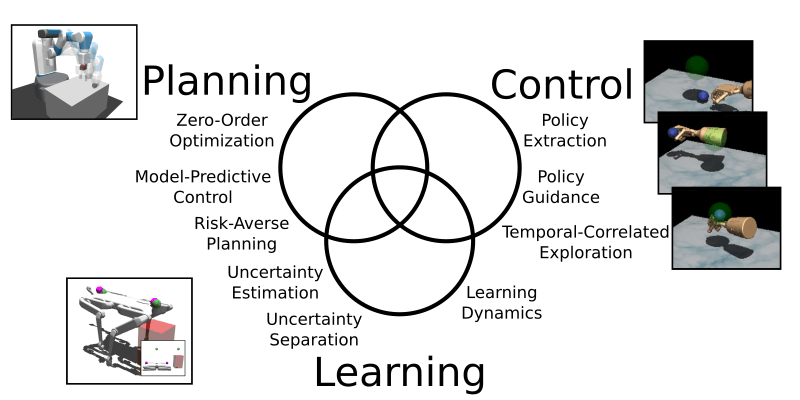
The goal of this project is to bring efficient learning-based control methods to real robots. A promising direction to learning from a few trials is to separate the task. First, train a model of the interactions with the environment and then use model-based reinforcement learning or model-based planning to control the robot. In a first work, we have explored the use of our equation learning framework for the forward model and obtained unparalleled performance on a cart-pendulum system [![]() ]. However, we found that it does not scale yet to relevant robotic systems.
]. However, we found that it does not scale yet to relevant robotic systems.
A widely used method in model-based reinforcement learning is the Cross-Entropy Method (CEM), which is a zero-order optimization scheme to compute good action sequences. In [![]() ] we have improved this method by replacing the uncorrelated sampling of actions with a temporal-correlated-based sampling (colored noise). As a result, we were able to reduce the computational cost of CEM by a factor of 3-22 while yielding a performance increase of up to 10 times in a variety of challenging robotic tasks (see figure).
] we have improved this method by replacing the uncorrelated sampling of actions with a temporal-correlated-based sampling (colored noise). As a result, we were able to reduce the computational cost of CEM by a factor of 3-22 while yielding a performance increase of up to 10 times in a variety of challenging robotic tasks (see figure).
Even with our improvements, it is still challenging to run such a model-based planning method in real-time on a robot with a high update frequency. Thus we set out to extract neural network policies from the data generated by a model-based planning algorithm. A challenging task, as it turns out since naive policy learning methods fail to learn from such a stochastic planning algorithm. We have proposed an adaptive guided policy search method [![]() ] that is able to distill strong policies for challenging simulated robotics tasks.
] that is able to distill strong policies for challenging simulated robotics tasks.
The next step in our aim to run these algorithms on a real robot is to make them risk-aware. We extend the learned dynamics models with the ability to estimate their prediction uncertainty. In fact, the models distinguish between uncertainty due to lack of data and inherent unpredictability (noise). We demonstrate on several continuous control tasks how to obtain active learning and risk-averse planning to avoid dangerous situations [![]() ]. This is an important step towards safe reinforcement learning on real hardware.
]. This is an important step towards safe reinforcement learning on real hardware.
[![]() ] Pinneri, C., Sawant, S., Blaes, S., Achterhold, J., Stueckler, J., Rolinek, M., Martius, G. Sample-efficient Cross-Entropy Method for Real-time Planning In Conference on Robot Learning 2020, 2020
] Pinneri, C., Sawant, S., Blaes, S., Achterhold, J., Stueckler, J., Rolinek, M., Martius, G. Sample-efficient Cross-Entropy Method for Real-time Planning In Conference on Robot Learning 2020, 2020
[![]() ] Pinneri*, C., Sawant*, S., Blaes, S., Martius, G. Extracting Strong Policies for Robotics Tasks from Zero-order Trajectory Optimizers In 9th International Conference on Learning Representations (ICLR 2021), May 2021
] Pinneri*, C., Sawant*, S., Blaes, S., Martius, G. Extracting Strong Policies for Robotics Tasks from Zero-order Trajectory Optimizers In 9th International Conference on Learning Representations (ICLR 2021), May 2021
[![]() ] Vlastelica*, M., Blaes*, S., Pinneri, C., Martius, G. Risk-Averse Zero-Order Trajectory Optimization In 5th Annual Conference on Robot Learning, November 2021
] Vlastelica*, M., Blaes*, S., Pinneri, C., Martius, G. Risk-Averse Zero-Order Trajectory Optimization In 5th Annual Conference on Robot Learning, November 2021
iCEM

Sample-efficient Cross-Entropy Method for Real-time Planning
Trajectory optimizers for model-based reinforcement learning, such as the Cross-Entropy Method (CEM), can yield compelling results even in high-dimensional control tasks and sparse-reward environments. However, their sampling inefficiency prevents them from being used for real-time planning and control. We propose an improved version of the CEM algorithm for fast planning, with novel additions including temporally-correlated actions and memory, requiring 2.7-22x less samples and yielding a performance increase of 1.2-10x in high-dimensional control problems.
[![]() ] Pinneri, C., Sawant, S., Blaes, S., Achterhold, J., Stueckler, J., Rolinek, M., Martius, G. Sample-efficient Cross-Entropy Method for Real-time Planning In Conference on Robot Learning 2020, 2020
] Pinneri, C., Sawant, S., Blaes, S., Achterhold, J., Stueckler, J., Rolinek, M., Martius, G. Sample-efficient Cross-Entropy Method for Real-time Planning In Conference on Robot Learning 2020, 2020
Policy Extraction

Extracting Strong Policies for Robotics Tasks from Zero-order Trajectory Optimizers
Solving high-dimensional, continuous robotic tasks is a challenging optimization problem. Model-based methods that rely on zero-order optimizers like the cross-entropy method (CEM) have so far shown strong performance and are considered state-of-the-art in the model-based reinforcement learning community. However, this success comes at the cost of high computational complexity, being therefore not suitable for real-time control. In this paper, we propose a technique to jointly optimize the trajectory and distill a policy, which is essential for fast execution in real robotic systems. Our method builds upon standard approaches, like guidance cost and dataset aggregation, and introduces a novel adaptive factor which prevents the optimizer from collapsing to the learner's behavior at the beginning of the training. The extracted policies reach unprecedented performance on challenging tasks as making a humanoid stand up and opening a door without reward shaping.
[![]() ] Pinneri*, C., Sawant*, S., Blaes, S., Martius, G. Extracting Strong Policies for Robotics Tasks from Zero-order Trajectory Optimizers In 9th International Conference on Learning Representations (ICLR 2021), May 2021
] Pinneri*, C., Sawant*, S., Blaes, S., Martius, G. Extracting Strong Policies for Robotics Tasks from Zero-order Trajectory Optimizers In 9th International Conference on Learning Representations (ICLR 2021), May 2021
Risk-Averse Planning

Risk-Averse Zero-Order Trajectory Optimization
We introduce a simple but effective method for managing risk in zero-order trajectory optimization that involves probabilistic safety constraints and balancing of optimism in the face of epistemic uncertainty and pessimism in the face of aleatoric uncertainty of an ensemble of stochastic neural networks. Various experiments indicate that the separation of uncertainties is essential to performing well with data-driven MPC approaches in uncertain and safety-critical control environments.
[![]() ] Vlastelica*, M., Blaes*, S., Pinneri, C., Martius, G. Risk-Averse Zero-Order Trajectory Optimization In 5th Annual Conference on Robot Learning, November 2021
] Vlastelica*, M., Blaes*, S., Pinneri, C., Martius, G. Risk-Averse Zero-Order Trajectory Optimization In 5th Annual Conference on Robot Learning, November 2021
Members




Publications