Reinforcement Learning and Control
Model-based Reinforcement Learning and Planning
Causal Reasoning in RL
Intrinsically Motivated Hierarchical Learner
Regularity as Intrinsic Reward for Free Play
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Natural and Robust Walking from Generic Rewards
Goal-conditioned Offline Planning
Offline Diversity Under Imitation Constraints
Learning Diverse Skills for Local Navigation
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Intrinsically Motivated Learning

The goal of intrinsically-motivated reinforcement learning (RL) is for agents to explore environments efficiently, similar to the curious play of children. We study intrinsic motivation to maximize future task capabilities. Initially, we focus on learning progress and surprise as motivators [![]() ]. We also explore the causal influence of a robot as a driver for exploration [
]. We also explore the causal influence of a robot as a driver for exploration [![]() ]. We investigate intrinsic reward signals, inductive biases, and learning frameworks to optimize exploration. Recently, we consider predicted information gain as an internal drive to improve exploration efficiency and to learn capable world models [
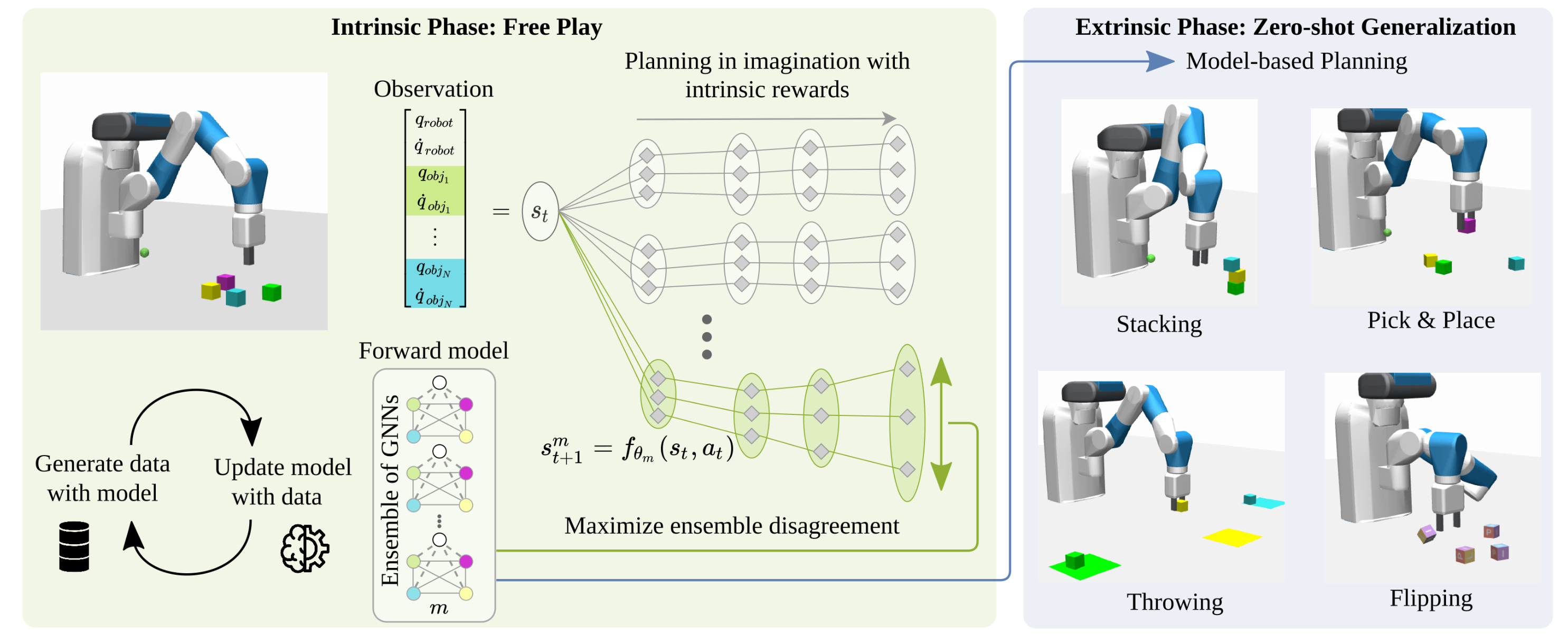
]. We investigate intrinsic reward signals, inductive biases, and learning frameworks to optimize exploration. Recently, we consider predicted information gain as an internal drive to improve exploration efficiency and to learn capable world models [![]() ]. We find that structured world models allow for relational inductive biases that are suitable for tasks with many objects. Combined with our planning method [
]. We find that structured world models allow for relational inductive biases that are suitable for tasks with many objects. Combined with our planning method [![]() ], we obtain a task-agnostic free-play behavior that explores what can be done in the environment. Using the online-planning method, a robotic arm can then perform tasks such as block stacking without further training, so we achieved zero-shot task generalization.
], we obtain a task-agnostic free-play behavior that explores what can be done in the environment. Using the online-planning method, a robotic arm can then perform tasks such as block stacking without further training, so we achieved zero-shot task generalization.
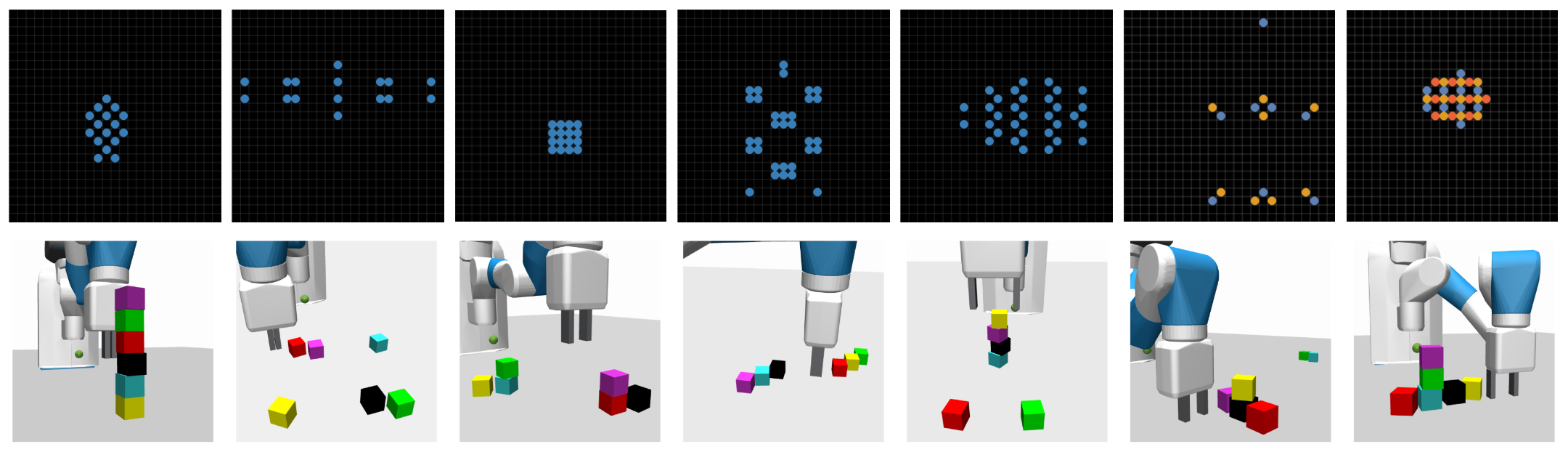
Inspired by child development, we postulate that the search for structure partially guides exploration. We propose Regularity as Intrinsic Reward (RaIR) [] in model-based RL. RaIR is a measure of regularity of a scene and is computed using Shannon Entropy of a suitable scene representation. We find that RaIR and epistemic uncertainty promote autonomous construction of structures during free play which also leads to improved zero-shot task performance in construction tasks.
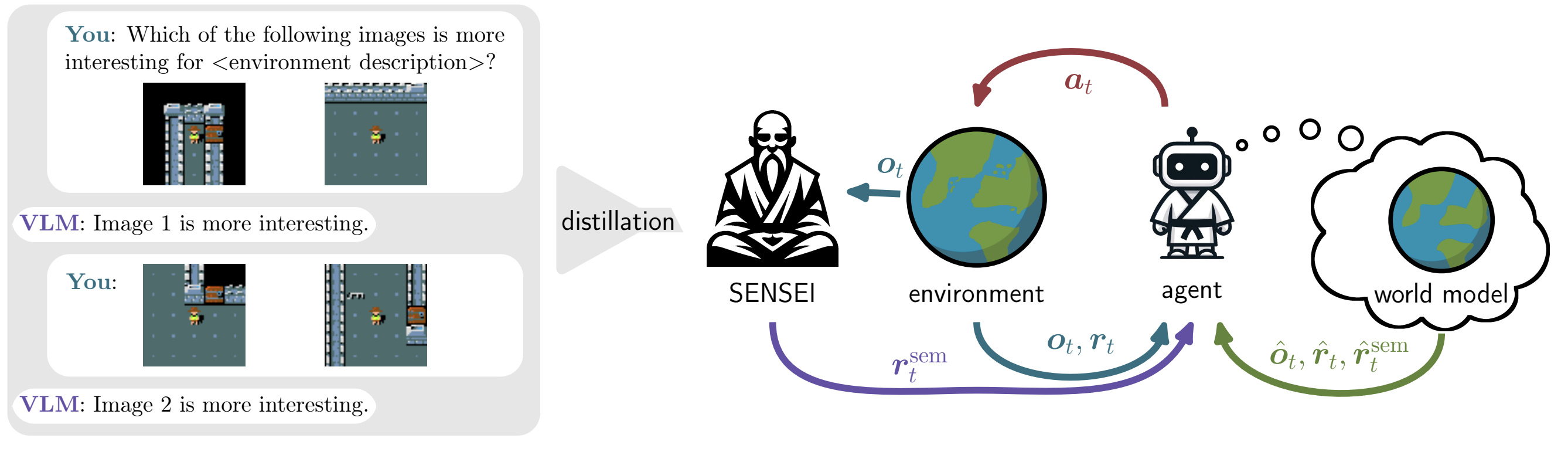
We further investigate how meaningful behaviors can emerge. Foundation models are a great source of high-level knowledge. We propose SEmaNtically Sensible ExploratIon (SENSEI)[![]() ], a framework to equip model-based RL agents with intrinsic motivation from vision language models for semantically meaningful behavior. We observe more directed exploration towards "reasonable" behavior during free-play that translates into better world-models and improved downstream performance.
], a framework to equip model-based RL agents with intrinsic motivation from vision language models for semantically meaningful behavior. We observe more directed exploration towards "reasonable" behavior during free-play that translates into better world-models and improved downstream performance.