Social Foundations of Computation
Members
Publications
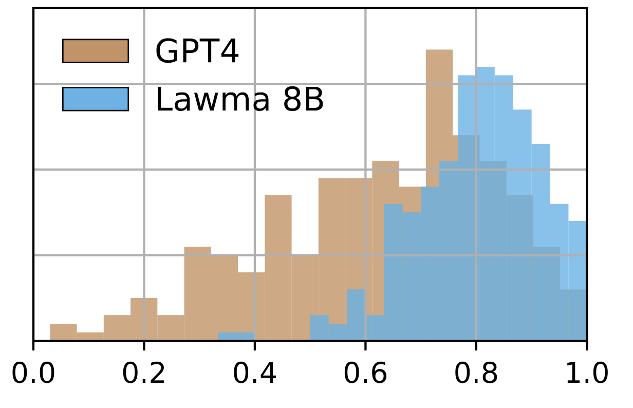
Caption: Distribution of accuracy across all tasks for GPT4 and Lawma. Lawma achieves mean accuracy of 82%, whereas GPT-4 achieves mean accuracy 62%.


Lawma: The Power of Specialization for Legal Tasks
A lightly finetuned Llama-3 model vastly outperforms GPT-4 on more than 100 annotation tasks take from the U.S. Supreme Court and U.S. Appeals Courts database.
Members
Publications
Social Foundations of Computation
Conference Paper
Lawma: The Power of Specialization for Legal Tasks
Dominguez-Olmedo, R., Nanda, V., Abebe, R., Bechtold, S., Engel, C., Frankenreiter, J., Gummadi, K., Hardt, M., Livermore, M.
The Thirteenth International Conference on Learning Representations (ICLR 2025), January 2025 (Accepted)
ArXiv
Code
BibTeX