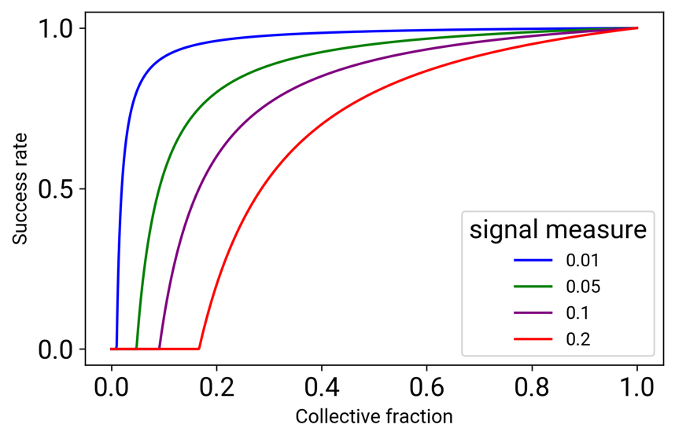
The collective plants a hidden rare signal in the data and exploits the signal at test time. Success grows rapidly as a function of the fraction of workers participating. Experiments with language models on freelancer resumes confirm our theoretical prediction.
We propose a theoretical model of algorithmic collective action. Participating workers modify their data in a coordinated manner in order to steer the learning algorithm toward a desired outcome. Even small collectives can have significant influence [].
We initiate a principled study of algorithmic collective action on digital platforms that deploy machine learning algorithms. We propose a simple theoretical model of a collective interacting with a firm’s learning algorithm. The collective pools the data of participating individuals and executes an algorithmic strategy by instructing participants how to modify their own data to achieve a collective goal. We investigate the consequences of this model in three fundamental learning-theoretic settings: nonparametric optimal learning, parametric risk minimization, and gradient-based optimization. In each setting, we come up with coordinated algorithmic strategies and characterize natural success criteria as a function of the collective’s size. Complementing our theory, we conduct systematic experiments on a skill classification task involving tens of thousands of resumes from a gig platform for freelancers. Through more than two thousand model training runs of a BERT-like language model, we see a striking correspondence emerge between our empirical observations and the predictions made by our theory. Taken together, our theory and experiments broadly support the conclusion that algorithmic collectives of exceedingly small fractional size can exert significant control over a platform’s learning algorithm.