Motion Synthesis

Capturing human motion is one of the building blocks for digital humans. It is also a fundamental requirement for analyzing and synthesizing motion from text or audio which is important in the context of immersive telepresence in VR (low-budget motion generation from audio), or AI-based assistants (text- / audio-driven animation of an avatar).
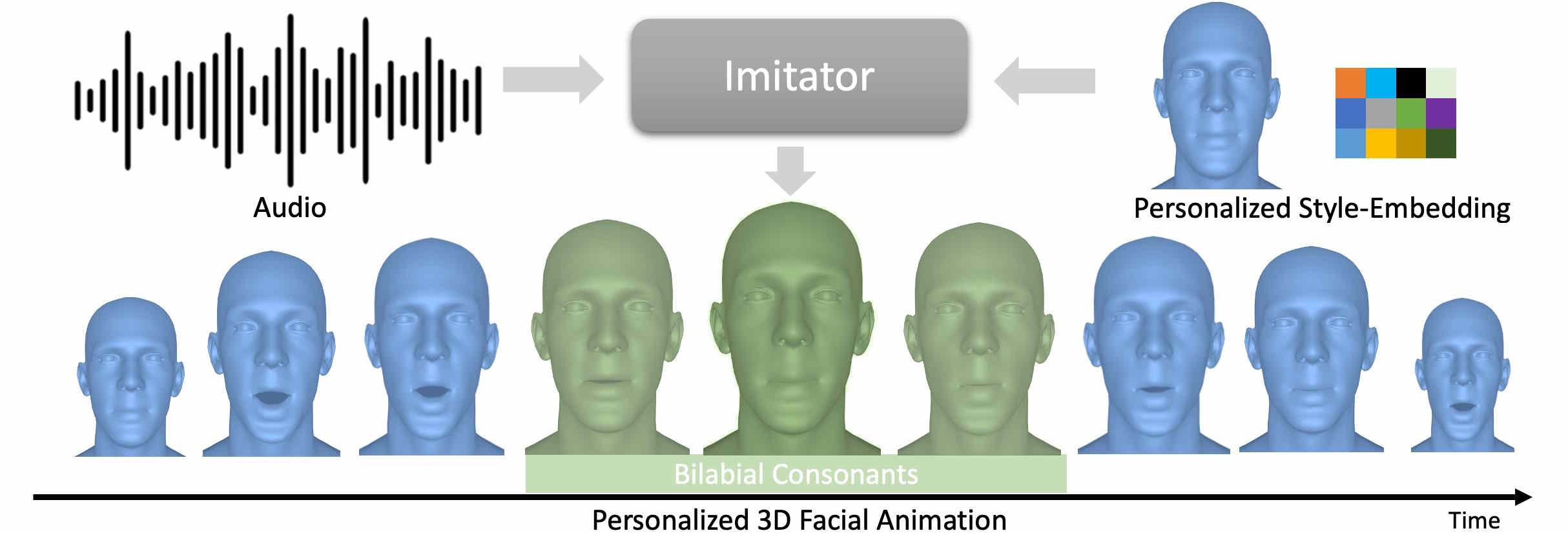
Generating 3D facial motion from audio is an active research field. In contrast to 2D methods, we are concentrating on 3D motion estimation to be compatible with 3D digital human representations. Most 3D face animation methods rely on neural network architectures that regress facial expressions that are generic or animations of a predefined set of subjects. In contrast to those, we aim at highly personalized facial expressions by adapting the expression synthesis based on a few samples of the target subject (e.g., using a 2-minute video of the subject). In Imitator, we show how a transformer-based architecture with a general style-agnostic module and a personalized motion decoder can be facilitated to reach this goal. In 3DiFace, we employ a diffusion-based technique that is additionally specialized towards editability, where artists can define the keyframes of an animation.
While the aforementioned methods focus on generating facial motion that fits into a talking stream of audio, we also explore text-guided motion generation of entire bodies. COMAND is building an action-aware motion manifold from unlabeled datasets of motion leveraging a latent space in frequency space. It allows for compositing novel animations of a sequence of actions with smooth transitions. While methods like COMAND can generate plausible motion sequences, they are not scene-aware. This results in collisions of the human with objects in the scene and animations that are physically not possible. To generate scene-aware human motions, we introduced TeSMo. It is based on a denoising diffusion model which is first trained on general scene-agnostic motion and then fine-tuned on scene-aware motion. Using text and action/goal positions as input, it generates a walking trajectory and corresponding motions, including interaction motions.