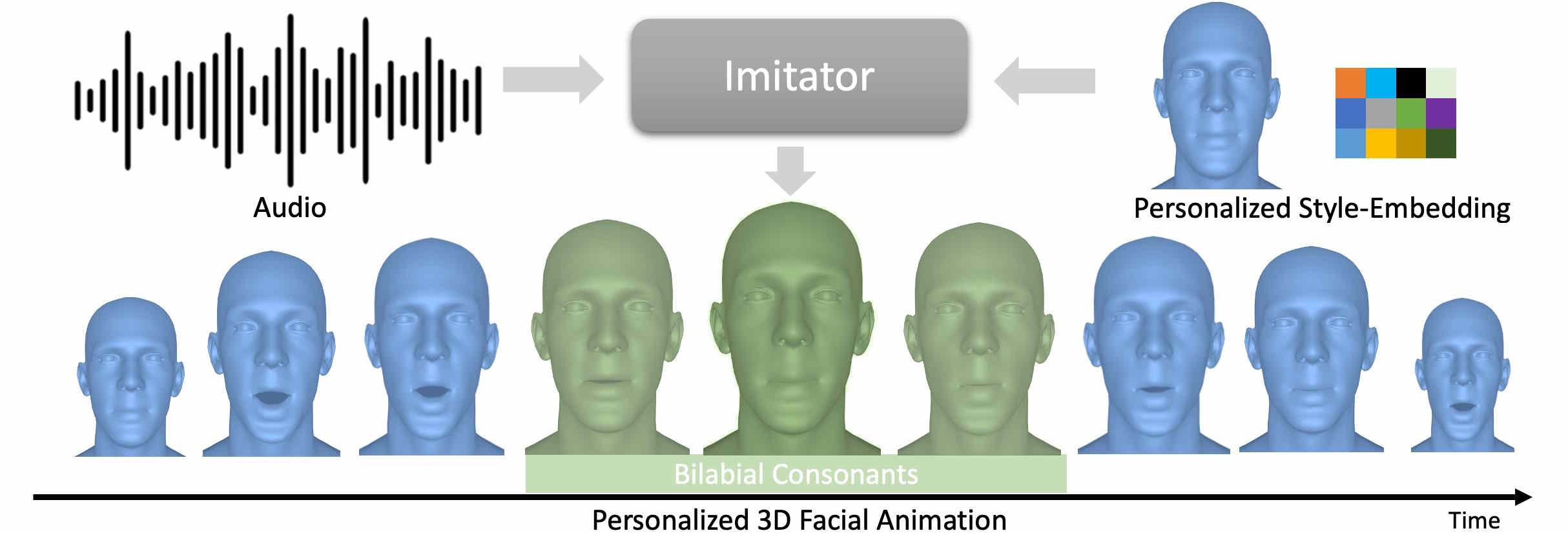
Imitator: Personalized Speech-driven 3D Facial Animation
Generating 3D facial animation sequences from audio.
Imitator learns identity-specific details from a short input video of a subject and produces novel facial expressions matching the identity-specific speaking style. A style-agnostic transformer is trained on a large expression dataset which we use as a prior for audio-driven expressions.
This website uses cookies to ensure you get the best experience. Learn more.