(Generative) Appearance Modelling and Editing
For applications like immersive telepresence in AR or VR, we are aiming for complete avatars that can adapt during run time, e.g., when changing the light. In addition, we want to be able to generate new content which also includes entire appearances of a human that can be used by an AI agent to communicate with an actual human. To this end, we are exploring (generative) appearance modelling and editing methods.
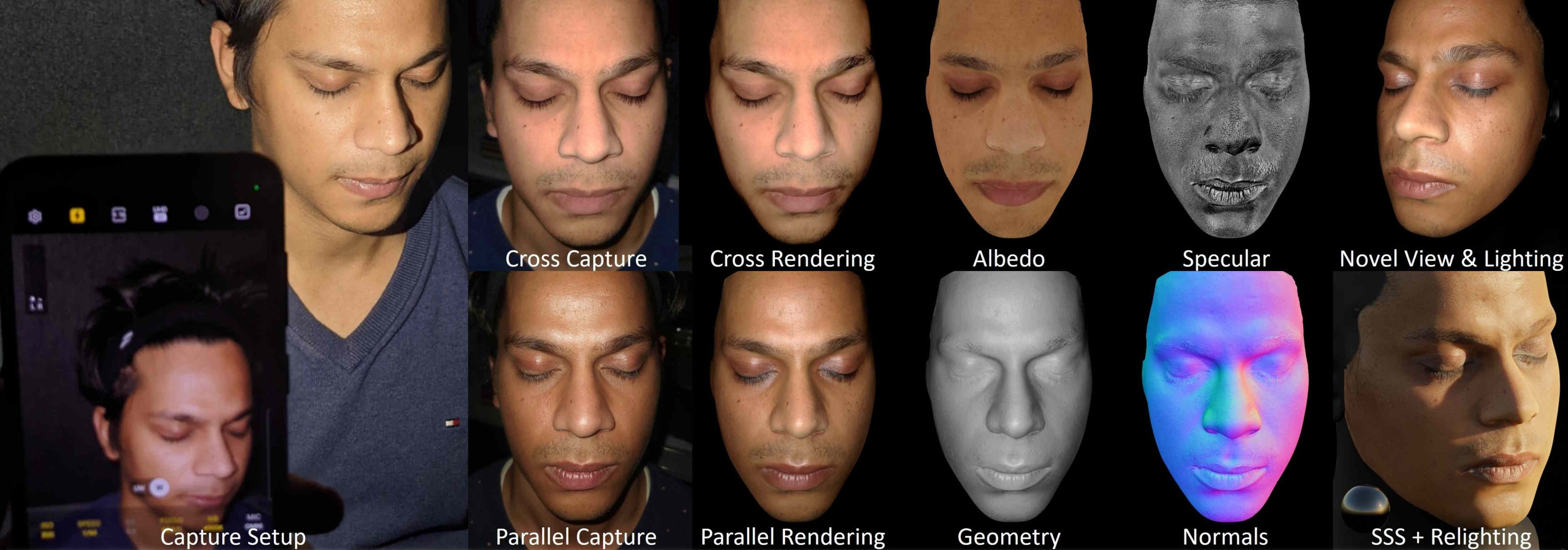
Following classical computer graphics, there are heuristics that are inspired by physics to handle for example the garment deformations or skin reflection properties. In CaPhy, we show how to reconstruct a human avatar with a decomposition in body and garment layers. During animation the garment layers can be deformed using a physics imitator network which is trained to reproduce captured sample poses of the human, and additional physics constraints from simulation. In PolFace, we demonstrate that we can recover the skin reflectance by estimating the parameters of a Disney-BRDF model from a smartphone video using polarization filters (on the flashlight and the camera). This allows us to render the reconstructed face under novel light settings in standard graphics pipelines.
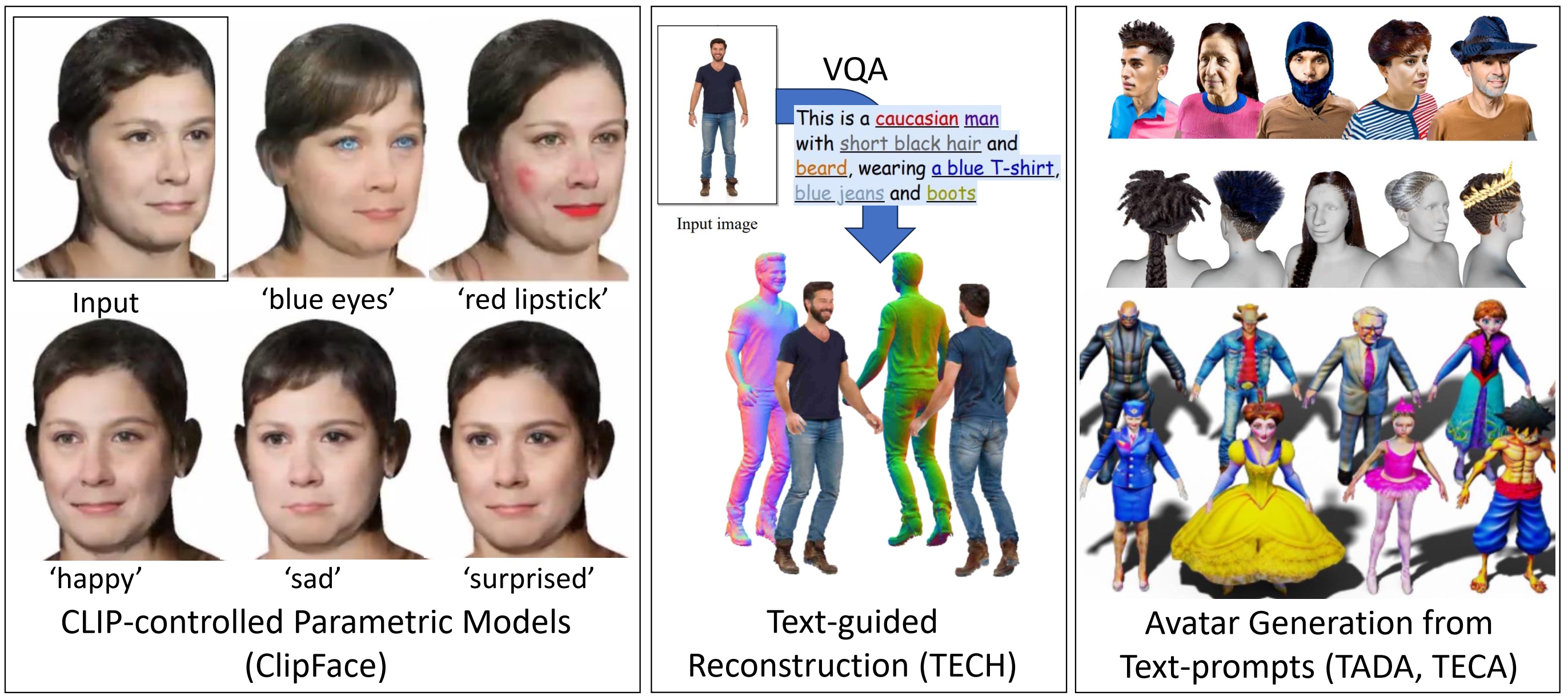
Different from the change of illumination, we explored the editing of already captured appearances using CLIP-based loss formulations. Based on textual inputs, ClipFace optimizes the appearance of a mesh within an appearance manifold spanned by a StyleGAN-like texture model to match the text descriptions. It allows us to change facial attributes like eye or lip color, and also facial expressions defined by morphable model parameters.
To create completely new content, we explored generative image diffusion models for the creation of avatars, but also the completion of avatars. In TECA and TADA, we demonstrate how compositional and animatable characters can be generated, respectively. We use the 2D image prior to distill a consistent 3D representation of the characters, by placing virtual cameras around the character and using multi-view reconstruction pipelines based on 3D neural rendering. The resulting avatars are rich in details and can be used as assets in down-stream applications like video games. Especially for future research, we see an immense potential that image and video priors could be used to learn motions of humans.