Research Overview

The main theme of the research group is to capture the real world and to (re-)synthesize it in virtual and augmented realities using low-cost commodity hardware. It includes the modeling of the human body, tracking, as well as the reconstruction and interaction with the environment. The digitization is needed for various applications in AR/VR as well as in movie (post-)production. Teleconferencing and working in AR/VR is of high interest and will have a high impact on society. It will change the way we communicate, how and where we work and live. A realistic reproduction of appearances and motions is key for such applications, to enable an immersive interaction. Especially, capturing natural motions and expressions of a human as well as the photorealistic reproduction of images under novel views are very challenging. But with the rise of deep learning methods and, especially, neural rendering, we see immense progress to succeed in these challenges.
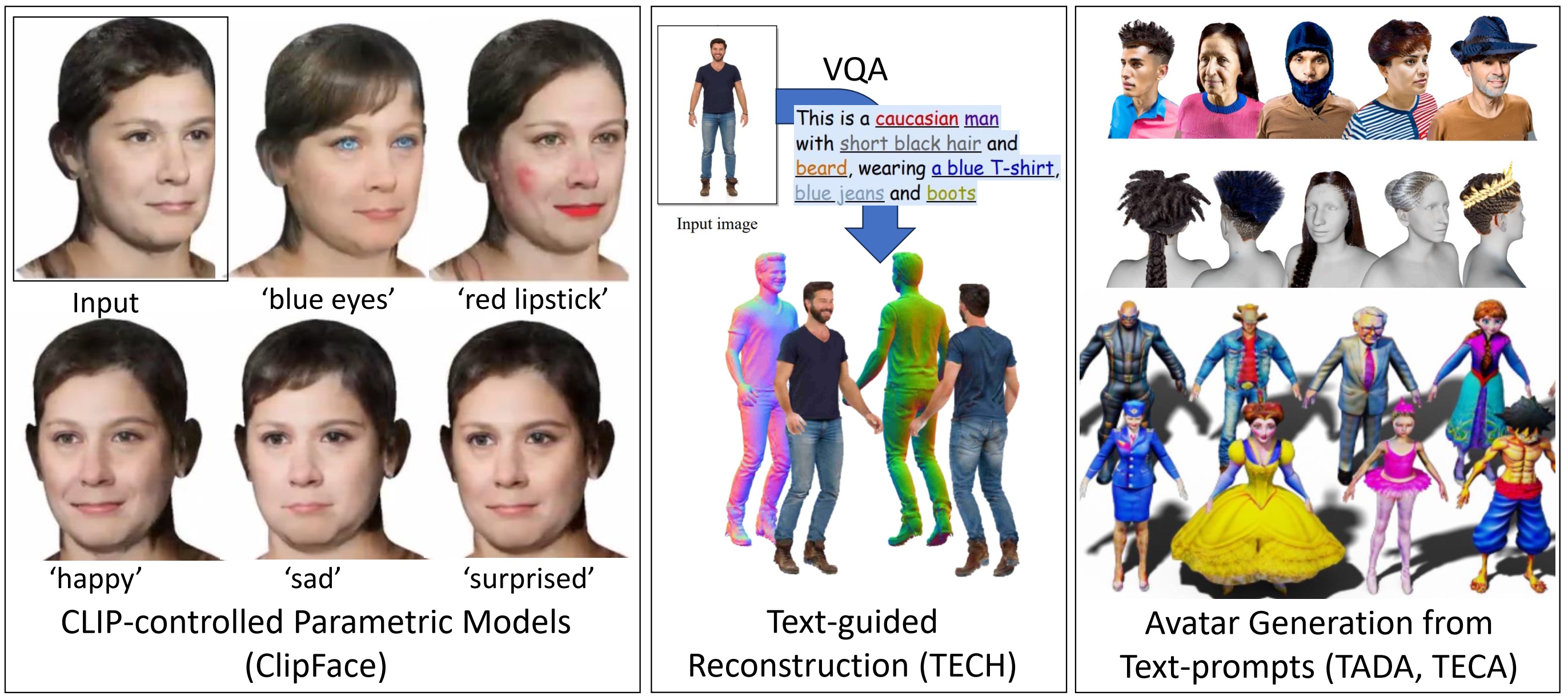
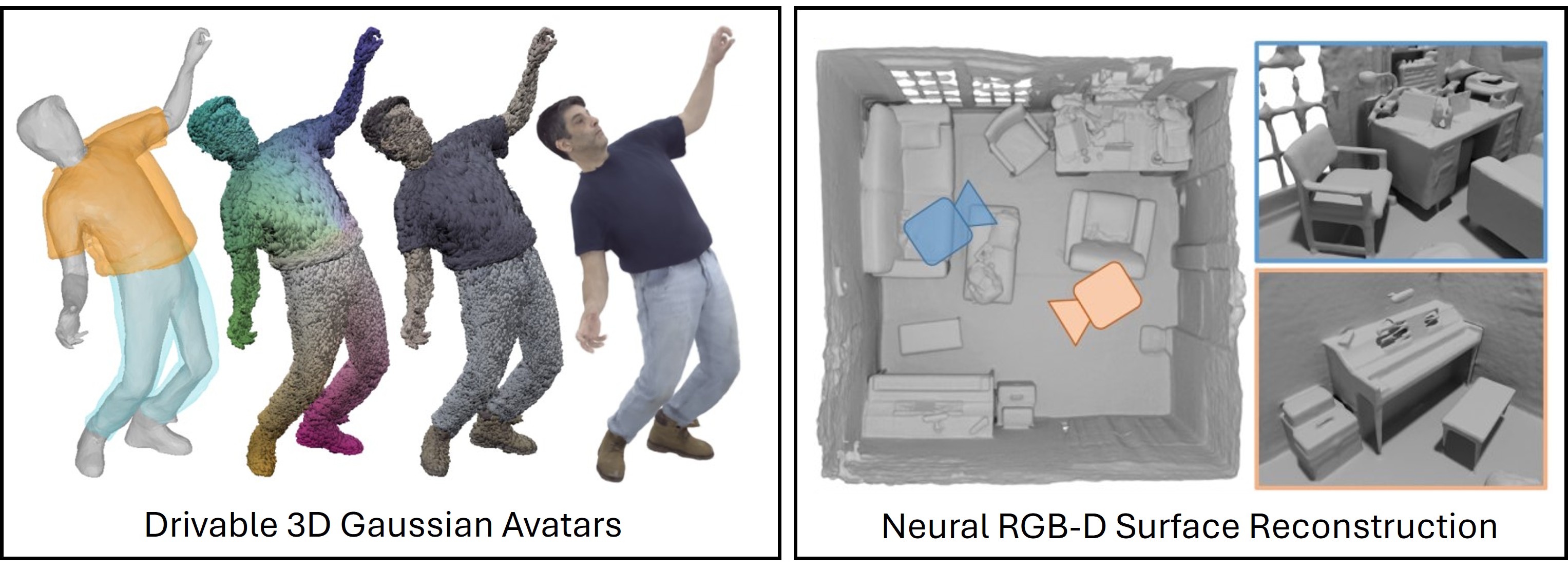
For these neural rendering methods, the underlying representation of appearance, geometry and motion are of paramount importance. Within this research group, we work on novel (neural) scene representations that allow for controllability, editability as well as for generalization and composition. Specifically, we concentrate on 3D/4D representations for humans that can capture the fine scale details of the body shape, facial expressions, hair, and the dynamics of clothing. The reconstructed avatars can be reposed while their appearance and surface is automatically adjusted in a plausible way, and for example wrinkles of clothing occur and disappear, or hair is moving.
To generate motion sequences of these avatars, we develop motion synthesis approaches that can drive them based on a variety of input modalities, like video, audio, or only text. These input modalities not only control the content, but also the style of a motion.
Research Fields & Projects
Digital Humans in Motion
Digital Multi-Media Forensics
Digitization of Objects and Scenes
Capturing Humans, Objects and Scenes
Motion Synthesis

(Generative) Appearance Modelling and Editing