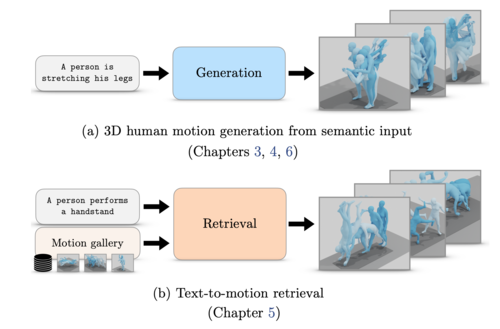
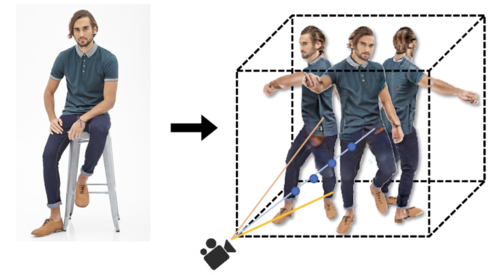
3D human motions are at the core of many applications in the film industry,
healthcare, augmented reality, virtual reality and video games. However, these
applications often rely on expensive and time-consuming motion capture data.
The goal of this thesis is to explore generative models as an alternative
route to obtain 3D human motions. More specifically, our aim is to allow a
natural language interface as a means to control the generation process. To
this end, we develop a series of models that synthesize realistic and diverse
motions following the semantic inputs.
In our first contribution, described in Chapter 3, we address the challenge
of generating human motion sequences conditioned on specific action categories.
We introduce ACTOR, a conditional variational autoencoder (VAE) that learns an
action-aware latent representation for human motions. We show significant gains
over existing methods thanks to our new Transformer-based VAE formulation,
encoding and decoding SMPL pose sequences through a single motion-level
embedding.
In our second contribution, described in Chapter 4, we go beyond categorical
actions, and dive into the task of synthesizing diverse 3D human motions
from textual descriptions allowing a larger vocabulary and potentially more
fine-grained control. Our work stands out from previous research by not
deterministically generating a single motion sequence, but by synthesizing
multiple, varied sequences from a given text. We propose TEMOS, building on
our VAE-based ACTOR architecture, but this time integrating a pretrained text
encoder to handle large-vocabulary natural language inputs.
In our third contribution, described in Chapter 5, we address the adjacent
task of text-to-3D human motion retrieval, where the goal is to search in a
motion collection by querying via text. We introduce a simple yet effective
approach, named TMR, building on our earlier model TEMOS, by integrating a
contrastive loss to enhance the structure of the cross-modal latent space. Our
findings emphasize the importance of retaining the motion generation loss in
conjunction with contrastive training for improved results. We establish a new
evaluation benchmark and conduct analyses on several protocols.
In our fourth contribution, described in Chapter 6, we introduce a new
problem termed as “multi-track timeline control” for text-driven 3D human
motion synthesis. Instead of a single textual prompt, users can organize multiple
prompts in temporal intervals that may overlap. We introduce STMC, a test-time
denoising method that can be integrated with any pre-trained motion diffusion
model. Our evaluations demonstrate that our method generates motions that
closely match the semantic and temporal aspects of the input timelines.
In summary, our contributions in this thesis are as follows: (i) we develop a
generative variational autoencoder, ACTOR, for action-conditioned generation of
human motion sequences, (ii) we introduce TEMOS, a text-conditioned generative
model that synthesizes diverse human motions from textual descriptions, (iii)
we present TMR, a new approach for text-to-3D human motion retrieval, (iv) we
propose STMC, a method for timeline control in text-driven motion synthesis,
enabling the generation of detailed and complex motions.