A Dynamic Model of Human-ML Collaboration
Human-ML collaboration is increasingly used in various applications, from content moderation in social media to predicting diagnoses in healthcare and making hiring decisions in human resources. Companies that implement human-ML collaborative systems face three crucial challenges: 1) ML models learn from past human decisions, which are often only an approximation to the ground truth (noisy labels); 2) ML models are rolled out to help future human decisions, affecting the data-generating process of human-ML collaboration that then influences future updates to ML models; and 3) the quality of the human-ML collaborative prediction of the ground truth may change as a function of incentives and other human factors. These challenges create a dynamic learning process.
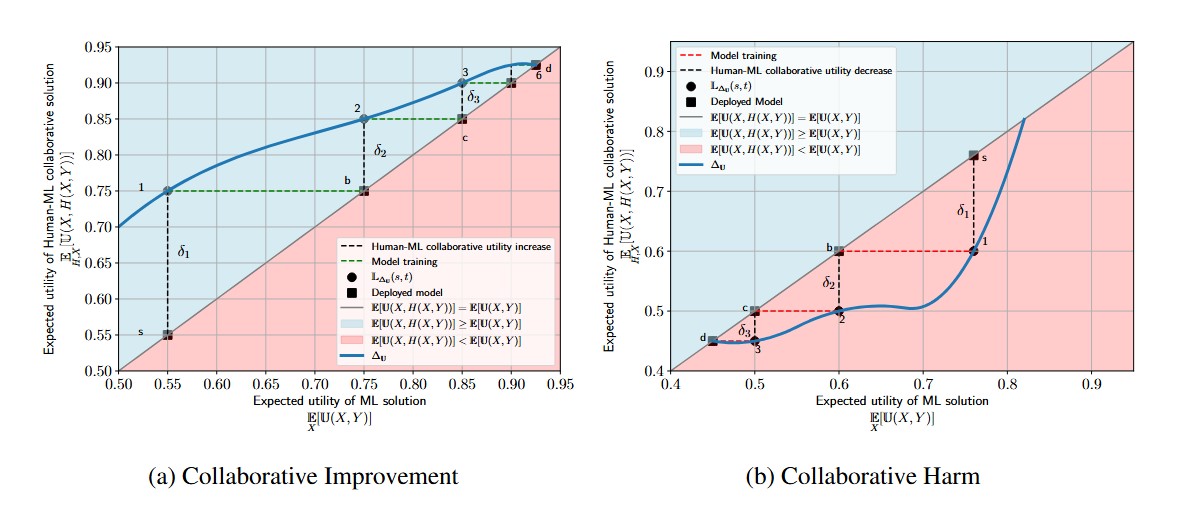
Without access to the ground truth, it is often difficult to know whether the learning process will reach an equilibrium state with a good approximation of the ground truth, if it is interrupted at a sub-optimal level, or if it does not reach a stable state at all.
For intuition, we can focus on the decision of a healthcare company to develop and deploy an ML model to predict medical diagnoses from patient visits. The problem is made difficult by the fact that a doctor's diagnoses can be wrong, and it is often too costly or time-consuming to identify the indisputable ground truth---i.e., the underlying true diagnosis of a patient---so the company typically uses all diagnoses to train their ML model, without distinction between good or bad diagnoses. In addition, the company typically evaluates the algorithm's performance based on its ability to match those same doctor diagnoses, potentially replicating their mistakes. The dynamic deployment of updates to ML models that support doctor diagnoses could lead to a downward spiral of human+ML performance if the company deploys a bad model and the bad model adversely affects doctor decisions. Or, it can lead to continuous improvement until it reaches a stable point that is a good approximation to the indisputable ground truth. Without (potentially costly) efforts to measure the ground truth, the company has no way of distinguishing between downward spirals or continuous improvements.
This raises a multitude of empirical questions regarding the governing mechanisms of this dynamic system. How do humans improve on ML predictions of different quality levels, and do financial incentives matter? Will the dynamic learning process converge to a good equilibrium even without the company knowing the actual ground truth labels?