In TRADYN [], we learn a terrain- and robot-aware dynamics model for navigation control in a 2D simulation. It extends Explore the Context (EtC) [] which learns an adaptive dynamics model which is conditioned on past motion experience and uses this model for sampling-based model-predictive control. EtC is extended by additional inputting terrain features from a map at the predicted location of the robot.
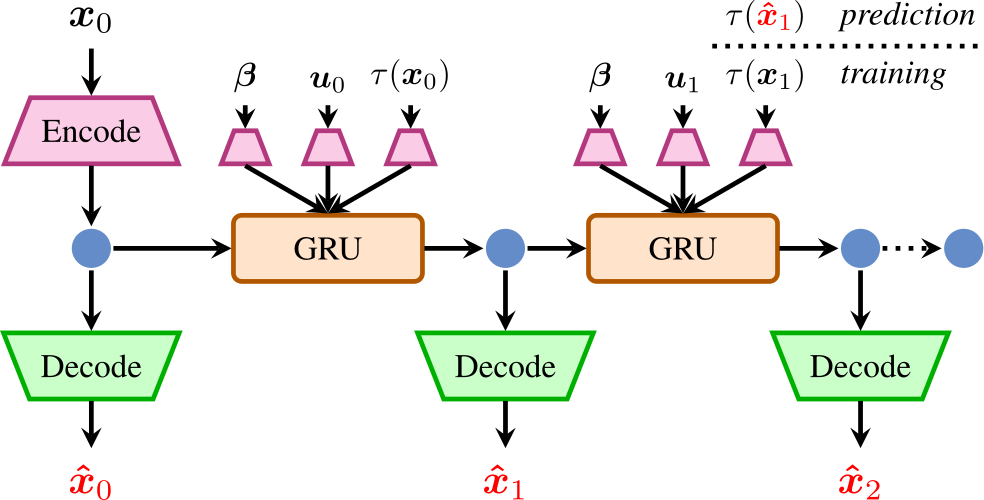
In autonomous navigation settings, several quantities can be subject to variations. Terrain properties such as friction coefficients may vary over time depending on the location of the robot. Also, the dynamics of the robot may change due to, e.g., different payloads, changing the system's mass, or wear and tear, changing actuator gains or joint friction. An autonomous agent should thus be able to adapt to such variations. In this paper, we develop a novel probabilistic, terrain- and robot-aware forward dynamics model, termed TRADYN, which is able to adapt to the above-mentioned variations. It builds on recent advances in meta-learning forward dynamics models based on Neural Processes. We evaluate our method in a simulated 2D navigation setting with a unicycle-like robot and different terrain layouts with spatially varying friction coefficients. In our experiments, the proposed model exhibits lower prediction error for the task of long-horizon trajectory prediction, compared to non-adaptive ablation models. We also evaluate our model on the downstream task of navigation planning, which demonstrates improved performance in planning control-efficient paths by taking robot and terrain properties into account.
In this paper, we learn dynamics models for parametrized families of dynamical systems with varying properties. The dynamics models are formulated as stochastic processes conditioned on a latent context variable which is inferred from observed transitions of the respective system. The probabilistic formulation allows us to compute an action sequence which, for a limited number of environment interactions, optimally explores the given system within the parametrized family. This is achieved by steering the system through transitions being most informative for the context variable. We demonstrate the effectiveness of our method for exploration on a non-linear toy-problem and two well-known reinforcement learning environments.
 ].
]. 



