Benchmarking LLMs on prediction tasks derived from survey data
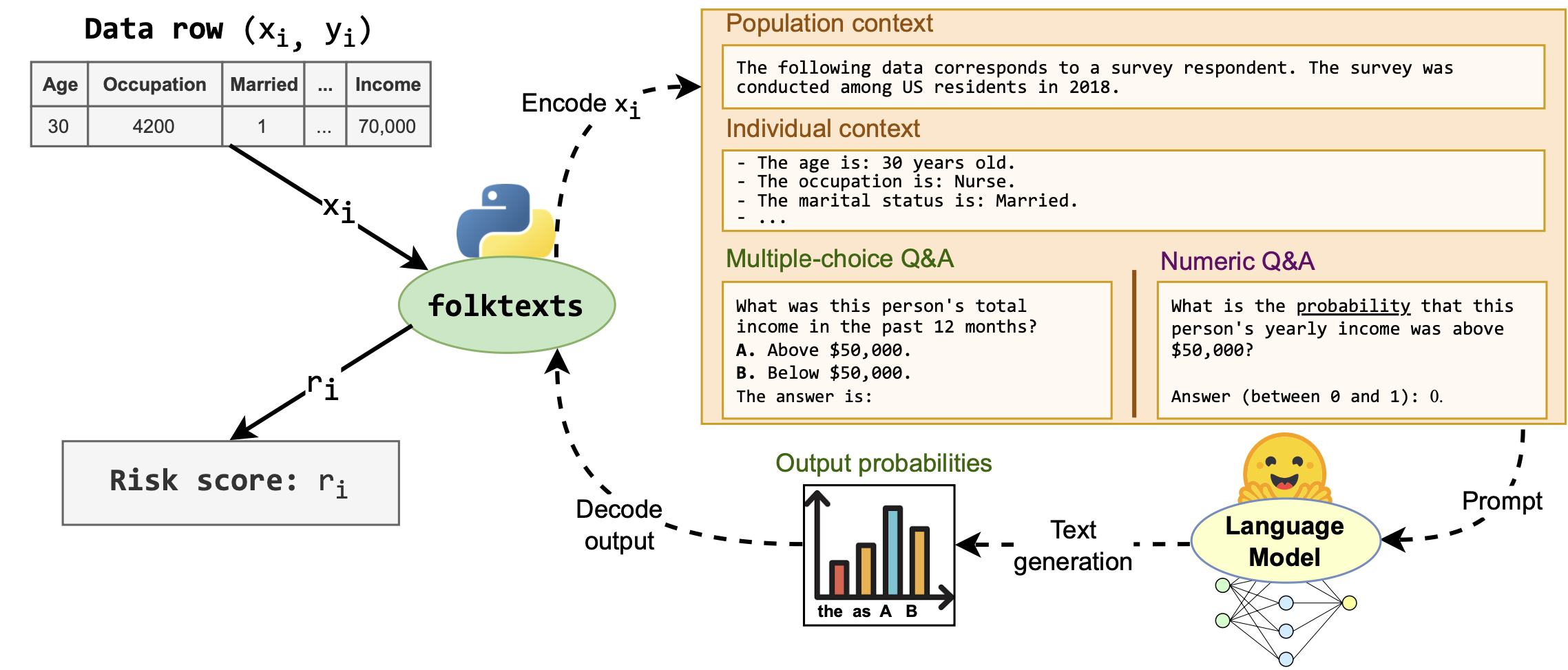
Folktexts offers a Python software package together with ready to use natural language question-answering datasets to evaluate accuracy, calibration and fairness of LLMs on human outcome prediction tasks.
>> pip install folktexts
Folktexts provides a suite of Q&A datasets for evaluating uncertainty, calibration, accuracy and fairness of LLMs on individual outcome prediction tasks. It provides a flexible framework to derive prediction tasks from survey data, translates them into natural text prompts, extracts LLM-generated risk scores, and computes statistical properties of these risk scores by comparing them to the ground truth outcomes.
Current question-answering benchmarks predominantly focus on accuracy in realizable prediction tasks. Conditioned on a question and answer-key, does the most likely token match the ground truth? Such benchmarks necessarily fail to evaluate language models' ability to quantify outcome uncertainty. In this work, we focus on the use of language models as risk scores for unrealizable prediction tasks. We introduce folktexts, a software package to systematically generate risk scores using large language models, and evaluate them against benchmark prediction tasks. Specifically, the package derives natural language tasks from US Census data products, inspired by popular tabular data benchmarks. A flexible API allows for any task to be constructed out of 28 census features whose values are mapped to prompt-completion pairs. We demonstrate the utility of folktexts through a sweep of empirical insights on 16 recent large language models, inspecting risk scores, calibration curves, and diverse evaluation metrics. We find that zero-shot risk sores have high predictive signal while being widely miscalibrated: base models overestimate outcome uncertainty, while instruction-tuned models underestimate uncertainty and generate over-confident risk scores.