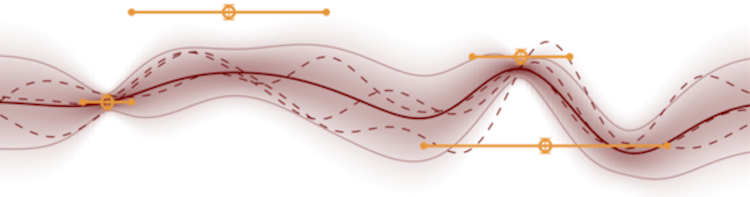
In deterministic optimization, line searches are a standard tool ensuring stability and efficiency. Where only stochastic gradients are available, no direct equivalent has so far been formulated, because uncertain gradients do not allow for a strict sequence of decisions collapsing the search space. We construct a probabilistic line search by combining the structure of existing deterministic methods with notions from Bayesian optimization. Our method retains a Gaussian process surrogate of the univariate optimization objective, and uses a probabilistic belief over the Wolfe conditions to monitor the descent. The algorithm has very low computational cost, and no user-controlled parameters. Experiments show that it effectively removes the need to define a learning rate for stochastic gradient descent.
[You can find the matlab research code under `attachments' below. The zip-file contains a minimal working example. The docstring in probLineSearch.m contains additional information. A more polished implementation in C++ will be published here at a later point. For comments and questions about the code please write to mmahsereci@tue.mpg.de.]
We deliver a call to arms for probabilistic numerical methods: algorithms for numerical tasks, including linear algebra, integration, optimization and solving differential equations, that return uncertainties in their calculations. Such uncertainties, arising from the loss of precision induced by numerical calculation with limited time or hardware, are important for much contemporary science and industry. Within applications such as climate science and astrophysics, the need to make decisions on the basis of computations with large and complex data have led to a renewed focus on the management of numerical uncertainty. We describe how several seminal classic numerical methods can be interpreted naturally as probabilistic inference. We then show that the probabilistic view suggests new algorithms that can flexibly be adapted to suit application specifics, while delivering improved empirical performance. We provide concrete illustrations of the benefits of probabilistic numeric algorithms on real scientific problems from astrometry and astronomical imaging, while highlighting open problems with these new algorithms. Finally, we describe how probabilistic numerical methods provide a coherent framework for identifying the uncertainty in calculations performed with a combination of numerical algorithms (e.g. both numerical optimizers and differential equation solvers), potentially allowing the diagnosis (and control) of error sources in computations.
Predicting the time at which the integral over a stochastic process reaches a target level is a value of interest in many applications. Often, such computations have to be made at low cost, in real time. As an intuitive example that captures many features of this problem class, we choose progress bars, a ubiquitous element of computer user interfaces. These predictors are usually based on simple point estimators, with no error modelling. This leads to fluctuating behaviour confusing to the user. It also does not provide a distribution prediction (risk values), which are crucial for many other application areas. We construct and empirically evaluate a fast, constant cost algorithm using a Gauss-Markov process model which provides more information to the user.
We study a probabilistic numerical method for the solution of both
boundary and initial value problems that returns a joint Gaussian
process posterior over the solution. Such methods have concrete value
in the statistics on Riemannian manifolds, where non-analytic ordinary
differential equations are involved in virtually all computations. The
probabilistic formulation permits marginalising the uncertainty of the
numerical solution such that statistics are less sensitive to
inaccuracies. This leads to new Riemannian algorithms for mean value
computations and principal geodesic analysis. Marginalisation also
means results can be less precise than point estimates, enabling a
noticeable speed-up over the state of the art. Our approach is an
argument for a wider point that uncertainty caused by numerical
calculations should be tracked throughout the pipeline of machine
learning algorithms.
Model-based control is essential for compliant controland force control in many modern complex robots, like humanoidor disaster robots. Due to many unknown and hard tomodel nonlinearities, analytical models of such robots are oftenonly very rough approximations. However, modern optimizationcontrollers frequently depend on reasonably accurate models,and degrade greatly in robustness and performance if modelerrors are too large. For a long time, machine learning hasbeen expected to provide automatic empirical model synthesis,yet so far, research has only generated feasibility studies butno learning algorithms that run reliably on complex robots.In this paper, we combine two promising worlds of regressiontechniques to generate a more powerful regression learningsystem. On the one hand, locally weighted regression techniquesare computationally efficient, but hard to tune due to avariety of data dependent meta-parameters. On the other hand,Bayesian regression has rather automatic and robust methods toset learning parameters, but becomes quickly computationallyinfeasible for big and high-dimensional data sets. By reducingthe complexity of Bayesian regression in the spirit of local modellearning through variational approximations, we arrive at anovel algorithm that is computationally efficient and easy toinitialize for robust learning. Evaluations on several datasetsdemonstrate very good learning performance and the potentialfor a general regression learning tool for robotics.
Four decades after their invention, quasi-Newton methods are still state of the art in unconstrained numerical optimization. Although not usually interpreted thus, these are learning algorithms that fit a local quadratic approximation to the objective function. We show that many, including the most popular, quasi-Newton methods can be interpreted as approximations of Bayesian linear regression under varying prior assumptions. This new notion elucidates some shortcomings of classical algorithms, and lights the way to a novel nonparametric quasi-Newton method, which is able to make more efficient use of available information at computational cost similar to its predecessors.
Four decades after their invention, quasi- Newton methods are still state of the art in unconstrained numerical optimization. Although not usually interpreted thus, these are learning algorithms that fit a local quadratic approximation to the objective function. We show that many, including the most popular, quasi-Newton methods can be interpreted as approximations of Bayesian linear regression under varying prior assumptions. This new notion elucidates some shortcomings of classical algorithms, and lights the way to a novel nonparametric quasi-Newton method, which is able to make more efficient use of available information at computational cost similar to its predecessors.
Contemporary global optimization algorithms are based on local measures of utility, rather than a probability measure over location and value of the optimum. They thus attempt to collect low function values, not to learn about the optimum. The reason for the absence of probabilistic global optimizers is that the corresponding inference problem is intractable in several ways. This paper develops desiderata for probabilistic optimization algorithms, then presents a concrete algorithm which addresses each of the computational intractabilities with a sequence of approximations and explicitly adresses the decision problem of maximizing information gain from each evaluation.
Latent Dirichlet Allocation models discrete data as a mixture of discrete distributions, using Dirichlet beliefs over the mixture weights. We study a variation of this concept, in which the documents' mixture weight beliefs are replaced with squashed Gaussian distributions. This allows documents to be associated with elements of a Hilbert space,
admitting kernel topic models (KTM), modelling temporal, spatial, hierarchical, social and other structure between documents. The main challenge is efficient approximate inference on the latent Gaussian. We present an approximate algorithm cast around a Laplace approximation in a transformed basis. The KTM can also be interpreted as a type of Gaussian process latent variable model, or as
a topic model conditional on document features, uncovering links between earlier work in these areas.
The exploration-exploitation trade-off is among the central challenges of reinforcement learning. The optimal Bayesian solution is intractable in general. This paper studies to what extent analytic statements about optimal learning are possible if all beliefs are Gaussian processes. A first order approximation of learning of both loss and dynamics, for nonlinear, time-varying systems in continuous time
and space, subject to a relatively weak restriction on the dynamics, is described by an infinite-dimensional partial differential equation. An approximate finitedimensional
projection gives an impression for how this result may be helpful.