FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
Paper Video
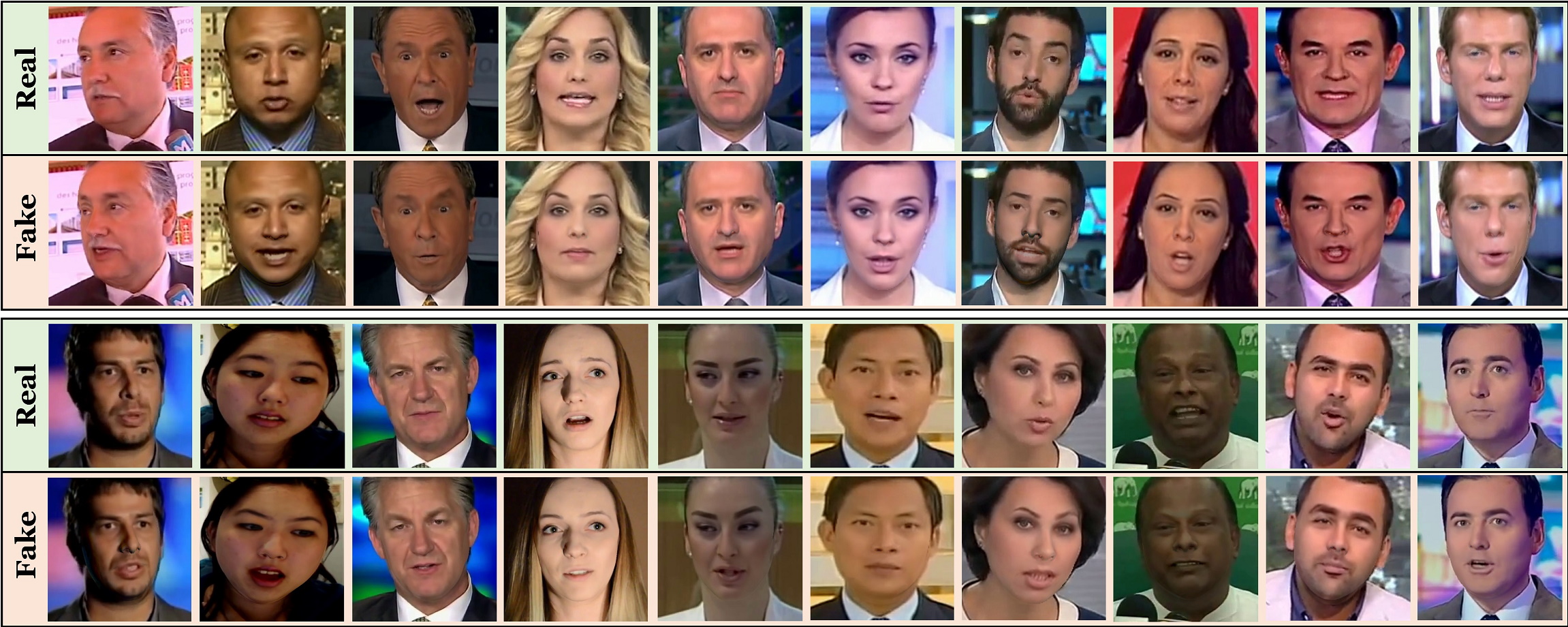
FaceForensics is a video dataset consisting of more than 500,000 frames containing faces from 1004 videos that can be used to study image or video forgeries. To create these videos we use an automatated version of the state of the art Face2Face approach. All videos are downloaded from Youtube and are cut down to short continuous clips that contain mostly frontal faces. In particular, we offer two versions of our dataset: Source-to-Target: where we reenact over 1000 videos with new facial expressions extracted from other videos, which e.g. can be used to train a classifier to detect fake images or videos. Selfreenactment: where we use Face2Face to reenact the facial expressions of videos with their own facial expressions as input to get pairs of videos, which e.g. can be used to train supervised generative refinement models.
| Author(s): | Rössler, Andreas and Cozzolino, Davide and Verdoliva, Luisa and Riess, Christian and Thies, Justus and Nießner, Matthias |
| Links: | |
| Journal: | arXiv |
| Year: | 2018 |
| Bibtex Type: | Article (article) |
| URL: | https://justusthies.github.io/posts/faceforensics/ |
| Electronic Archiving: | grant_archive |
BibTex
@article{roessler2018faceforensics,
title = {FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces},
journal = {arXiv},
abstract = {FaceForensics is a video dataset consisting of more than 500,000 frames containing faces from 1004 videos that can be used to study image or video forgeries. To create these videos we use an automatated version of the state of the art Face2Face approach. All videos are downloaded from Youtube and are cut down to short continuous clips that contain mostly frontal faces. In particular, we offer two versions of our dataset: Source-to-Target: where we reenact over 1000 videos with new facial expressions extracted from other videos, which e.g. can be used to train a classifier to detect fake images or videos. Selfreenactment: where we use Face2Face to reenact the facial expressions of videos with their own facial expressions as input to get pairs of videos, which e.g. can be used to train supervised generative refinement models.},
year = {2018},
slug = {roessler2018faceforensics},
author = {R{\"o}ssler, Andreas and Cozzolino, Davide and Verdoliva, Luisa and Riess, Christian and Thies, Justus and Nie{\ss}ner, Matthias},
url = {https://justusthies.github.io/posts/faceforensics/}
}