2024
ps
Xiu, Y., Liu, Z., Tzionas, D., Black, M. J.
PuzzleAvatar: Assembling 3D Avatars from Personal Albums
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published

ps
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y., Dong, Z., Bo, L., Xiu, Y., Han, X.
StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
ACM Transactions on Graphics, 43(6), ACM, December 2024 (article) To be published

hi
Mohan, M., Kuchenbecker, K. J.
Demonstration: OCRA - A Kinematic Retargeting Algorithm for Expressive Whole-Arm Teleoperation
Hands-on demonstration presented at the Conference on Robot Learning (CoRL), Munich, Germany, November 2024 (misc) Accepted
al
hi
ei
Andrussow, I., Sun, H., Martius, G., Kuchenbecker, K. J.
Demonstration: Minsight - A Soft Vision-Based Tactile Sensor for Robotic Fingertips
Hands-on demonstration presented at the Conference on Robot Learning (CoRL), Munich, Germany, November 2024 (misc) Accepted
hi
Bartels, J. U., Sanchez-Tamayo, N., Sedlmair, M., Kuchenbecker, K. J.
Active Haptic Feedback for a Virtual Wrist-Anchored User Interface
Hands-on demonstration presented at the ACM Symposium on User Interface Software and Technology (UIST), Pittsburgh, USA, October 2024 (misc) Accepted

OS Lab
Reinschmidt, M., Fortágh, J., Günther, A., Volchkov, V.
Reinforcement learning in cold atom experiments
nature communications, 15:8532, October 2024 (article)
rm
Yoder, Z., Rumley, E., Schmidt, I., Rothemund, P., Keplinger, C.
Hexagonal electrohydraulic modules for rapidly reconfigurable high-speed robots
Science Robotics, 9, September 2024 (article)
hi
ei
OS Lab
zwe-sw
Cao, C. G. L., Javot, B., Bhattarai, S., Bierig, K., Oreshnikov, I., Volchkov, V. V.
Fiber-Optic Shape Sensing Using Neural Networks Operating on Multispecklegrams
IEEE Sensors Journal, 24(17):27532-27540, September 2024 (article)

ps
Sanyal, S.
Leveraging Unpaired Data for the Creation of Controllable Digital Humans
Max Planck Institute for Intelligent Systems and Eberhard Karls Universität Tübingen, September 2024 (phdthesis) To be published

ps
Sun, J., Huang, L., Hongsong Wang, C. Z. J. Q., Islam, M. T., Xie, E., Zhou, B., Xing, L., Chandrasekaran, A., Black, M. J.
Localization and recognition of human action in 3D using transformers
Nature Communications Engineering , 13(125), September 2024 (article)

ps
Osman, A. A. A.
Realistic Digital Human Characters: Challenges, Models and Algorithms
University of Tübingen, September 2024 (phdthesis)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Rothemund, P., Ballardini, G., Keplinger, C., Kuchenbecker, K. J.
Cutaneous Electrohydraulic (CUTE) Wearable Devices for Pleasant Broad-Bandwidth Haptic Cues
Advanced Science, (2402461):1-14, September 2024 (article)

rm
Buchner, T. J. K., Fukushima, T., Kazemipour, A., Gravert, S., Prairie, M., Romanescu, P., Arm, P., Zhang, Y., Wang, X., Zhang, S. L., Walter, J., Keplinger, C., Katzschmann, R. K.
Electrohydraulic Musculoskeletal Robotic Leg for Agile, Adaptive, yet Energy-Efficient Locomotion
Nature Communications, 15(1), September 2024 (article)

hi
Tashiro, N., Faulkner, R., Melnyk, S., Rodriguez, T. R., Javot, B., Tahouni, Y., Cheng, T., Wood, D., Menges, A., Kuchenbecker, K. J.
Building Instructions You Can Feel: Edge-Changing Haptic Devices for Digitally Guided Construction
ACM Transactions on Computer-Human Interaction, September 2024 (article) Accepted
ei
Immer, A.
Advances in Probabilistic Methods for Deep Learning
ETH Zurich, Switzerland, September 2024, CLS PhD Program (phdthesis)

ps
Wall, J., Lefcourt, J., Jones, C., Doehring, C., O’Neill, D., Schneider, D., Steward, J., Krautwurst, J., Wong, T., Jones, B., Goodfellow, K., Schmitt, T., Gobush, K., Douglas-Hamilton, I., Pope, F., Schmidt, E., Palmer, J., Stokes, E., Reid, A., Elbroch, M. L., Kulits, P., Villeneuve, C., Matsanza, V., Clinning, G., Oort, J. V., Denninger-Snyder, K., Daati, A. P., Gold, W., Cunliffe, S., Craig, B., Cork, B., Burden, G., Goss, M., Hahn, N., Carroll, S., Gitonga, E., Rao, R., Stabach, J., Broin, F. D., Omondi, P., Wittemyer, G.
EarthRanger: An Open-Source Platform for Ecosystem Monitoring, Research, and Management
Methods in Ecology and Evolution, 13, British Ecological Society, September 2024 (article)
ei
Bizeul, A., Schölkopf, B., Allen, C.
A Probabilistic Model behind Self-Supervised Learning
Transactions on Machine Learning Research, September 2024 (article) To be published
hi
Rokhmanova, N., Martus, J., Faulkner, R., Fiene, J., Kuchenbecker, K. J.
Modeling Shank Tissue Properties and Quantifying Body Composition with a Wearable Actuator-Accelerometer Set
Extended abstract (1 page) presented at the American Society of Biomechanics Annual Meeting (ASB), Madison, USA, August 2024 (misc)
hi
Sharon, Y., Nevo, T., Naftalovich, D., Bahar, L., Refaely, Y., Nisky, I.
Augmenting Robot-Assisted Pattern Cutting With Periodic Perturbations – Can We Make Dry Lab Training More Realistic?
IEEE Transactions on Biomedical Engineering, August 2024 (article)

ps
Kulits, P., Feng, H., Liu, W., Abrevaya, V., Black, M. J.
Re-Thinking Inverse Graphics with Large Language Models
Transactions on Machine Learning Research, August 2024 (article)
ei
Chen*, W., Horwood*, J., Heo, J., Hernández-Lobato, J. M.
Leveraging Task Structures for Improved Identifiability in Neural Network Representations
Transactions on Machine Learning Research, August 2024, *equal contribution (article)
hi
Schulz, A., Serhat, G., Kuchenbecker, K. J.
Adapting a High-Fidelity Simulation of Human Skin for Comparative Touch Sensing
Extended abstract (1 page) presented at the American Society of Biomechanics Annual Meeting (ASB), Madison, USA, August 2024 (misc)
hi
Gong, Y.
Engineering and Evaluating Naturalistic Vibrotactile Feedback for Telerobotic Assembly
University of Stuttgart, Stuttgart, Germany, August 2024, Faculty of Design, Production Engineering and Automotive Engineering (phdthesis)
hi
Khojasteh, B., Solowjow, F., Trimpe, S., Kuchenbecker, K. J.
Multimodal Multi-User Surface Recognition with the Kernel Two-Sample Test
IEEE Transactions on Automation Science and Engineering, 21(3):4432-4447, July 2024 (article)
ei
Park, J.
A Measure-Theoretic Axiomatisation of Causality and Kernel Regression
University of Tübingen, Germany, July 2024 (phdthesis)
ei
Sajjadi, S. M. M.
Enhancement and Evaluation of Deep Generative Networks with Applications in Super-Resolution and Image Generation
University of Tübingen, Germany, July 2024 (phdthesis)
ei
lds
Kladny, K., Kügelgen, J. V., Schölkopf, B., Muehlebach, M.
Deep Backtracking Counterfactuals for Causally Compliant Explanations
Transactions on Machine Learning Research, July 2024 (article)

ps
Taheri, O.
Modelling Dynamic 3D Human-Object Interactions: From Capture to Synthesis
University of Tübingen, July 2024 (phdthesis) To be published
hi
Lev, H. K., Sharon, Y., Geftler, A., Nisky, I.
Errors in Long-Term Robotic Surgical Training
Work-in-progress paper (3 pages) presented at the EuroHaptics Conference, Lille, France, June 2024 (misc)
ei
Stimper, V.
Advancing Normalising Flows to Model Boltzmann Distributions
University of Cambridge, UK, Cambridge, June 2024, (Cambridge-Tübingen-Fellowship-Program) (phdthesis)
hi
zwe-rob
Rokhmanova, N., Martus, J., Faulkner, R., Fiene, J., Kuchenbecker, K. J.
GaitGuide: A Wearable Device for Vibrotactile Motion Guidance
Workshop paper (3 pages) presented at the ICRA Workshop on Advancing Wearable Devices and Applications Through Novel Design, Sensing, Actuation, and AI, Yokohama, Japan, May 2024 (misc)
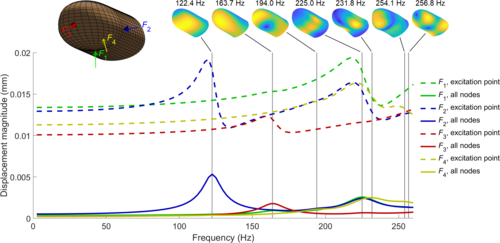
hi
Serhat, G., Kuchenbecker, K. J.
Fingertip Dynamic Response Simulated Across Excitation Points and Frequencies
Biomechanics and Modeling in Mechanobiology, 23, pages: 1369-1376, May 2024 (article)
hi
Sundaram, V. H., Smith, L., Turin, Z., Rentschler, M. E., Welker, C. G.
Three-Dimensional Surface Reconstruction of a Soft System via Distributed Magnetic Sensing
Workshop paper (3 pages) presented at the ICRA Workshop on Advancing Wearable Devices and Applications Through Novel Design, Sensing, Actuation, and AI, Yokohama, Japan, May 2024 (misc)
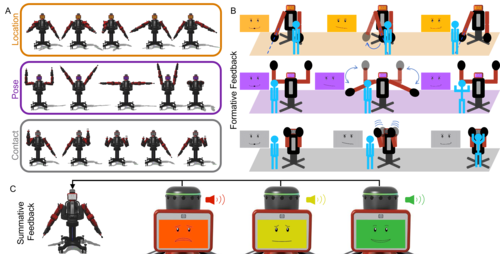
hi
Mohan, M., Nunez, C. M., Kuchenbecker, K. J.
Closing the Loop in Minimally Supervised Human-Robot Interaction: Formative and Summative Feedback
Scientific Reports, 14(10564):1-18, May 2024 (article)
ei
Schölkopf, B.
Grundfragen der künstlichen Intelligenz
astronomie - Das Magazin, 42, May 2024 (article)
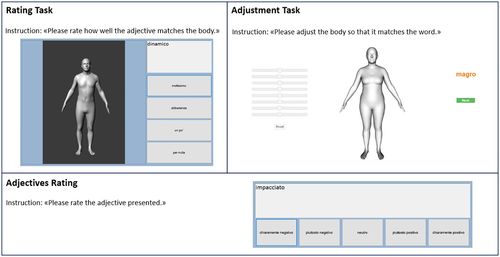
ps
Meneguzzo, P., Behrens, S. C., Pavan, C., Toffanin, T., Quiros-Ramirez, M. A., Black, M. J., Giel, K., Tenconi, E., Favaro, A.
Exploring Weight Bias and Negative Self-Evaluation in Patients with Mood Disorders: Insights from the BodyTalk Project,
Frontiers in Psychiatry, 15, Sec. Psychopathology, May 2024 (article)

ps
Li, C., Mellbin, Y., Krogager, J., Polikovsky, S., Holmberg, M., Ghorbani, N., Black, M. J., Kjellström, H., Zuffi, S., Hernlund, E.
The Poses for Equine Research Dataset (PFERD)
Nature Scientific Data, 11, May 2024 (article)
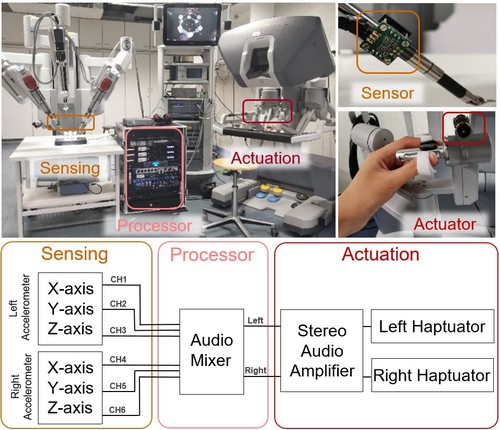
hi
Gong, Y., Mat Husin, H., Erol, E., Ortenzi, V., Kuchenbecker, K. J.
AiroTouch: Enhancing Telerobotic Assembly through Naturalistic Haptic Feedback of Tool Vibrations
Frontiers in Robotics and AI, 11(1355205):1-15, May 2024 (article)

hi
Javot, B., Nguyen, V. H., Ballardini, G., Kuchenbecker, K. J.
CAPT Motor: A Strong Direct-Drive Rotary Haptic Interface
Hands-on demonstration presented at the IEEE Haptics Symposium, Long Beach, USA, April 2024 (misc)
hi
Fazlollahi, F., Seifi, H., Ballardini, G., Taghizadeh, Z., Schulz, A., MacLean, K. E., Kuchenbecker, K. J.
Quantifying Haptic Quality: External Measurements Match Expert Assessments of Stiffness Rendering Across Devices
Work-in-progress paper (2 pages) presented at the IEEE Haptics Symposium, Long Beach, USA, April 2024 (misc)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Ballardini, G., Rothemund, P., Keplinger, C., Kuchenbecker, K. J.
Cutaneous Electrohydraulic (CUTE) Wearable Devices for Multimodal Haptic Feedback
Extended abstract (1 page) presented at the IEEE RoboSoft Workshop on Multimodal Soft Robots for Multifunctional Manipulation, Locomotion, and Human-Machine Interaction, San Diego, USA, April 2024 (misc)
ei
Zabel, S., Hennig, P., Nieselt, K.
VIPurPCA: Visualizing and Propagating Uncertainty in Principal Component Analysis
IEEE Transactions on Visualization and Computer Graphics, 30(4):2011-2022, April 2024 (article)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Ballardini, G., Rothemund, P., Keplinger, C., Kuchenbecker, K. J.
Cutaneous Electrohydraulic Wearable Devices for Expressive and Salient Haptic Feedback
Hands-on demonstration presented at the IEEE Haptics Symposium, Long Beach, USA, April 2024 (misc)
hi
rm
Sanchez-Tamayo, N., Yoder, Z., Ballardini, G., Rothemund, P., Keplinger, C., Kuchenbecker, K. J.
Demonstration: Cutaneous Electrohydraulic (CUTE) Wearable Devices for Expressive and Salient Haptic Feedback
Hands-on demonstration presented at the IEEE RoboSoft Conference, San Diego, USA, April 2024 (misc)
sf
Yasar, A. G., Chong, A., Dong, E., Gilbert, T., Hladikova, S., Mougan, C., Shen, X., Singh, S., Stoica, A., Thais, S.
Integration of Generative AI in the Digital Markets Act: Contestability and Fairness from a Cross-Disciplinary Perspective
LSE Legal Studies Working Paper, March 2024 (article)
ei
Besserve, M., Safavi, S., Schölkopf, B., Logothetis, N.
LFP transient events in macaque subcortical areas reveal network coordination across scales and structures: a simultaneous fMRI-electrophysiology study
Computational and Systems Neuroscience Meeting (COSYNE), March 2024 (poster)
hi
Allemang–Trivalle, A., Donjat, J., Bechu, G., Coppin, G., Chollet, M., Klaproth, O. W., Mitschke, A., Schirrmann, A., Cao, C. G. L.
Modeling Fatigue in Manual and Robot-Assisted Work for Operator 5.0
IISE Transactions on Occupational Ergonomics and Human Factors, 12(1-2):135-147, March 2024 (article)
ei
Shao, K., Xu, Y., Logothetis, N., Shen, Z., Besserve, M.
Koopman Spectral Analysis Uncovers the Temporal Structure of Spontaneous Neural Events
Computational and Systems Neuroscience Meeting (COSYNE), March 2024 (poster)
ei
Ortu, F.
Interpreting How Large Language Models Handle Facts and Counterfactuals through Mechanistic Interpretability
University of Trieste, Italy, March 2024 (mastersthesis)
ei
Mancini, M., Naeem, M. F., Xian, Y., Akata, Z.
Learning Graph Embeddings for Open World Compositional Zero-Shot Learning
IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(3):1545-1560, IEEE, New York, NY, March 2024 (article)