
2024
ps
Sanyal, S.
Leveraging Unpaired Data for the Creation of Controllable Digital Humans
Max Planck Institute for Intelligent Systems and Eberhard Karls Universität Tübingen, September 2024 (phdthesis) To be published

ps
Osman, A. A. A.
Realistic Digital Human Characters: Challenges, Models and Algorithms
University of Tübingen, September 2024 (phdthesis)

ei
Immer, A.
Advances in Probabilistic Methods for Deep Learning
ETH Zurich, Switzerland, September 2024, CLS PhD Program (phdthesis)
hi
Gong, Y.
Engineering and Evaluating Naturalistic Vibrotactile Feedback for Telerobotic Assembly
University of Stuttgart, Stuttgart, Germany, August 2024, Faculty of Design, Production Engineering and Automotive Engineering (phdthesis)
ei
Park, J.
A Measure-Theoretic Axiomatisation of Causality and Kernel Regression
University of Tübingen, Germany, July 2024 (phdthesis)
ei
Sajjadi, S. M. M.
Enhancement and Evaluation of Deep Generative Networks with Applications in Super-Resolution and Image Generation
University of Tübingen, Germany, July 2024 (phdthesis)

ps
Taheri, O.
Modelling Dynamic 3D Human-Object Interactions: From Capture to Synthesis
University of Tübingen, July 2024 (phdthesis) To be published
ei
Stimper, V.
Advancing Normalising Flows to Model Boltzmann Distributions
University of Cambridge, UK, Cambridge, June 2024, (Cambridge-Tübingen-Fellowship-Program) (phdthesis)
ei
Rahaman, N., Weiss, M., Wüthrich, M., Bengio, Y., Li, E., Pal, C., Schölkopf, B.
Language Models Can Reduce Asymmetry in Information Markets
arXiv:2403.14443, March 2024, Published as: Redesigning Information Markets in the Era of Language Models, Conference on Language Modeling (COLM) (techreport)
ei
Ortu, F.
Interpreting How Large Language Models Handle Facts and Counterfactuals through Mechanistic Interpretability
University of Trieste, Italy, March 2024 (mastersthesis)
ei
von Kügelgen, J.
Identifiable Causal Representation Learning
University of Cambridge, UK, Cambridge, February 2024, (Cambridge-Tübingen-Fellowship) (phdthesis)
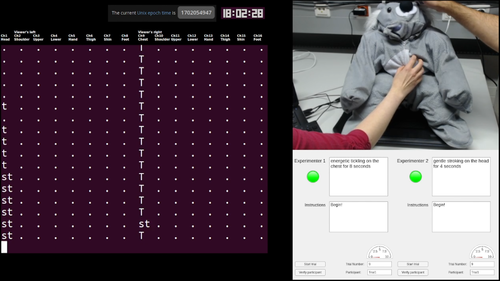
hi
Burns, R.
Creating a Haptic Empathetic Robot Animal That Feels Touch and Emotion
University of Tübingen, Tübingen, Germany, February 2024, Department of Computer Science (phdthesis)
ev
Achterhold, J., Guttikonda, S., Kreber, J. U., Li, H., Stueckler, J.
Learning a Terrain- and Robot-Aware Dynamics Model for Autonomous Mobile Robot Navigation
CoRR abs/2409.11452, 2024, Preprint submitted to Robotics and Autonomous Systems Journal. https://arxiv.org/abs/2409.11452 (techreport) Submitted
lds
Eberhard, O., Vernade, C., Muehlebach, M.
A Pontryagin Perspective on Reinforcement Learning
Max Planck Institute for Intelligent Systems, 2024 (techreport)

ps
Müller, L.
Self- and Interpersonal Contact in 3D Human Mesh Reconstruction
University of Tübingen, Tübingen, 2024 (phdthesis)
lds
Er, D., Trimpe, S., Muehlebach, M.
Distributed Event-Based Learning via ADMM
Max Planck Institute for Intelligent Systems, 2024 (techreport)

ps
Petrovich, M.
Natural Language Control for 3D Human Motion Synthesis
LIGM, Ecole des Ponts, Univ Gustave Eiffel, CNRS, 2024 (phdthesis)
ev
Baumeister, F., Mack, L., Stueckler, J.
Incremental Few-Shot Adaptation for Non-Prehensile Object Manipulation using Parallelizable Physics Simulators
CoRR abs/2409.13228, CoRR, 2024, Submitted to IEEE International Conference on Robotics and Automation (ICRA) 2025 (techreport) Submitted
2023
ei
Sakenyte, U.
Denoising Representation Learning for Causal Discovery
Université de Genèva, Switzerland, December 2023, external supervision (mastersthesis)
hi
Mohan, M.
Gesture-Based Nonverbal Interaction for Exercise Robots
University of Tübingen, Tübingen, Germany, October 2023, Department of Computer Science (phdthesis)
ei
Kofler, A.
Efficient Sampling from Differentiable Matrix Elements
Technical University of Munich, Germany, September 2023 (mastersthesis)
ei
Karimi, A.
Advances in Algorithmic Recourse: Ensuring Causal Consistency, Fairness, & Robustness
ETH Zurich, Switzerland, July 2023 (phdthesis)
ei
Kübler, J. M.
Learning and Testing Powerful Hypotheses
University of Tübingen, Germany, July 2023 (phdthesis)
ei
Gresele, L.
Learning Identifiable Representations: Independent Influences and Multiple Views
University of Tübingen, Germany, June 2023 (phdthesis)
ei
Paulus, M.
Learning with and for discrete optimization
ETH Zurich, Switzerland, May 2023, CLS PhD Program (phdthesis)
ei
Spieler, A. M.
Intrinsic complexity and mechanisms of expressivity of cortical neurons
University of Tübingen, Germany, March 2023 (mastersthesis)
lds
ei
Kladny, K.
CausalEffect Estimation by Combining Observational and Interventional Data
ETH Zurich, Switzerland, February 2023 (mastersthesis)
ei
Qui, Z.
Towards Generative Machine Teaching
Technical University of Munich, Germany, February 2023 (mastersthesis)
ei
Schneider, F.
ArchiSound: Audio Generation with Diffusion
ETH Zurich, Switzerland, January 2023, external supervision (mastersthesis)
ei
Dittrich, A.
Generation and Quantification of Spin in Robot Table Tennis
University of Stuttgart, Germany, January 2023 (mastersthesis)
ei
Jin, Z., Mihalcea, R.
Natural Language Processing for Policymaking
In Handbook of Computational Social Science for Policy, pages: 141-162, 7, (Editors: Bertoni, E. and Fontana, M. and Gabrielli, L. and Signorelli, S. and Vespe, M.), Springer International Publishing, 2023 (inbook)
ev
Strecke, M. F.
Object-Level Dynamic Scene Reconstruction With Physical Plausibility From RGB-D Images
Eberhard Karls Universität Tübingen, Tübingen, 2023 (phdthesis)
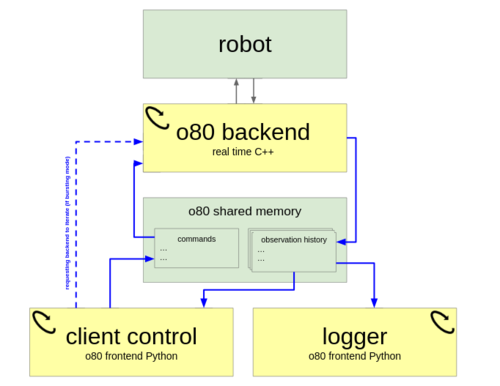
ei
Berenz, V., Widmaier, F., Guist, S., Schölkopf, B., Büchler, D.
Synchronizing Machine Learning Algorithms, Realtime Robotic Control and Simulated Environment with o80
Robot Software Architectures Workshop (RSA) 2023, ICRA, 2023 (techreport)
mms
Baluktsian, M.
Wave front shaping with zone plates: Fabrication and characterization of lenses for soft x-ray applications from standard to singular optics
Universität Stuttgart, Stuttgart (und Verlag Dr. Hut, München), 2023 (phdthesis)
mms
Bubeck, C.
Tailored perovskite-type oxynitride semiconductors and oxides with advanced physical properties
Technische Universität Darmstadt, Darmstadt, 2023 (phdthesis)
mms
Schulz, Frank Martin Ernst
Static and dynamic investigation of magnonic systems: materials, applications and modeling
Universität Stuttgart, Stuttgart, 2023 (phdthesis)
2022
ei
Biester, L., Demszky, D., Jin, Z., Sachan, M., Tetreault, J., Wilson, S., Xiao, L., Zhao, J.
Proceedings of the Second Workshop on NLP for Positive Impact (NLP4PI)
Association for Computational Linguistics, December 2022 (proceedings)
hi
Richardson, B.
Multi-Timescale Representation Learning of Human and Robot Haptic Interactions
University of Stuttgart, Stuttgart, Germany, December 2022, Faculty of Computer Science, Electrical Engineering and Information Technology (phdthesis)

ps
Choutas, V.
Reconstructing Expressive 3D Humans from RGB Images
ETH Zurich, Max Planck Institute for Intelligent Systems and ETH Zurich, December 2022 (phdthesis)
dlg
Sarvestani, L. A.
Mechanical Design, Development and Testing of Bioinspired Legged Robots for Dynamic Locomotion
Eberhard Karls Universität Tübingen, Tübingen , November 2022 (phdthesis)
ei
Neitz, A.
Towards learning mechanistic models at the right level of abstraction
University of Tübingen, Germany, November 2022 (phdthesis)

pf
Qiu, T., Jeong, M., Goyal, R., Kadiri, V., Sachs, J., Fischer, P.
Magnetic Micro-/Nanopropellers for Biomedicine
In Field-Driven Micro and Nanorobots for Biology and Medicine, pages: 389-410, 16, (Editors: Sun, Y. and Wang, X. and Yu, J.), Springer, Cham, 2022 (inbook)
re
Lieder, F., Prentice, M.
Life Improvement Science
In Encyclopedia of Quality of Life and Well-Being Research, Springer, November 2022 (inbook)
ei
Lu, C.
Learning Causal Representations for Generalization and Adaptation in Supervised, Imitation, and Reinforcement Learning
University of Cambridge, UK, Cambridge, October 2022, (Cambridge-Tübingen-Fellowship) (phdthesis)
ei
Liang, W.
Investigating Independent Mechanisms in Neural Networks
Université Paris-Saclay, France, October 2022 (mastersthesis)
hi
Nam, S.
Understanding the Influence of Moisture on Fingerpad-Surface Interactions
University of Tübingen, Tübingen, Germany, October 2022, Department of Computer Science (phdthesis)
ei
Keidar, D.
Modeling subgroup differences in fMRI data: disentangling subgroup-specific responses from shared ones
ETH Zurich, Switzerland, October 2022 (mastersthesis)
ei
Wenk, P.
Learning Time-Continuous Dynamics Models with Gaussian-Process-Based Gradient Matching
ETH Zurich, Switzerland, October 2022, CLS PhD Program (phdthesis)
ei
Feil, M.
Multi-Target Multi-Object Manipulation using Relational Deep Reinforcement Learning
Technnical University Munich, Germany, September 2022 (mastersthesis)
ei
Sliwa, J.
Independent Mechanism Analysis for High Dimensions
University of Tübingen, Germany, September 2022, (Graduate Training Centre of Neuroscience) (mastersthesis)