
2024
ps
Sanyal, S.
Leveraging Unpaired Data for the Creation of Controllable Digital Humans
Max Planck Institute for Intelligent Systems and Eberhard Karls Universität Tübingen, September 2024 (phdthesis) To be published

ps
Osman, A. A. A.
Realistic Digital Human Characters: Challenges, Models and Algorithms
University of Tübingen, September 2024 (phdthesis)

ei
Immer, A.
Advances in Probabilistic Methods for Deep Learning
ETH Zurich, Switzerland, September 2024, CLS PhD Program (phdthesis)
hi
Gong, Y.
Engineering and Evaluating Naturalistic Vibrotactile Feedback for Telerobotic Assembly
University of Stuttgart, Stuttgart, Germany, August 2024, Faculty of Design, Production Engineering and Automotive Engineering (phdthesis)
ei
Park, J.
A Measure-Theoretic Axiomatisation of Causality and Kernel Regression
University of Tübingen, Germany, July 2024 (phdthesis)
ei
Sajjadi, S. M. M.
Enhancement and Evaluation of Deep Generative Networks with Applications in Super-Resolution and Image Generation
University of Tübingen, Germany, July 2024 (phdthesis)

ps
Taheri, O.
Modelling Dynamic 3D Human-Object Interactions: From Capture to Synthesis
University of Tübingen, July 2024 (phdthesis) To be published
hi
Matthew, V., Simancek, R. E., Telepo, E., Machesky, J., Willman, H., Ismail, A. B., Schulz, A. K.
Empowering Change: The Role of Student Changemakers in Advancing Sustainability within Engineering Education
Proceedings of the American Society of Engineering Education (ASEE), June 2024, Victoria Matthew and Andrew K. Schulz contributed equally to this publication. (issue) In press
ei
Stimper, V.
Advancing Normalising Flows to Model Boltzmann Distributions
University of Cambridge, UK, Cambridge, June 2024, (Cambridge-Tübingen-Fellowship-Program) (phdthesis)
ei
Rahaman, N., Weiss, M., Wüthrich, M., Bengio, Y., Li, E., Pal, C., Schölkopf, B.
Language Models Can Reduce Asymmetry in Information Markets
arXiv:2403.14443, March 2024, Published as: Redesigning Information Markets in the Era of Language Models, Conference on Language Modeling (COLM) (techreport)
ei
von Kügelgen, J.
Identifiable Causal Representation Learning
University of Cambridge, UK, Cambridge, February 2024, (Cambridge-Tübingen-Fellowship) (phdthesis)
hi
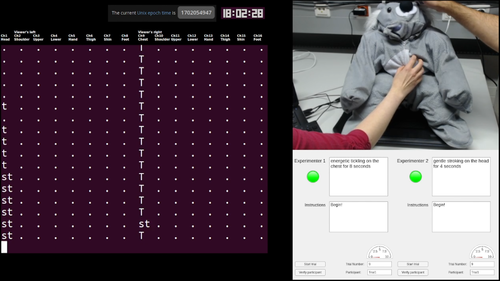
Burns, R.
Creating a Haptic Empathetic Robot Animal That Feels Touch and Emotion
University of Tübingen, Tübingen, Germany, February 2024, Department of Computer Science (phdthesis)
ev
Achterhold, J., Guttikonda, S., Kreber, J. U., Li, H., Stueckler, J.
Learning a Terrain- and Robot-Aware Dynamics Model for Autonomous Mobile Robot Navigation
CoRR abs/2409.11452, 2024, Preprint submitted to Robotics and Autonomous Systems Journal. https://arxiv.org/abs/2409.11452 (techreport) Submitted
lds
Eberhard, O., Vernade, C., Muehlebach, M.
A Pontryagin Perspective on Reinforcement Learning
Max Planck Institute for Intelligent Systems, 2024 (techreport)

ps
Müller, L.
Self- and Interpersonal Contact in 3D Human Mesh Reconstruction
University of Tübingen, Tübingen, 2024 (phdthesis)
lds
Er, D., Trimpe, S., Muehlebach, M.
Distributed Event-Based Learning via ADMM
Max Planck Institute for Intelligent Systems, 2024 (techreport)

ps
Petrovich, M.
Natural Language Control for 3D Human Motion Synthesis
LIGM, Ecole des Ponts, Univ Gustave Eiffel, CNRS, 2024 (phdthesis)
ev
Baumeister, F., Mack, L., Stueckler, J.
Incremental Few-Shot Adaptation for Non-Prehensile Object Manipulation using Parallelizable Physics Simulators
CoRR abs/2409.13228, CoRR, 2024, Submitted to IEEE International Conference on Robotics and Automation (ICRA) 2025 (techreport) Submitted

2023
sf
Barocas, S., Hardt, M., Narayanan, A.
Fairness in Machine Learning: Limitations and Opportunities
MIT Press, December 2023 (book)
ei
Jenny, D.
Navigating the Ocean of Biases: Political Bias Attribution in Language Models via Causal Structures
ETH Zurich, Switzerland, November 2023, external supervision (thesis)
rm
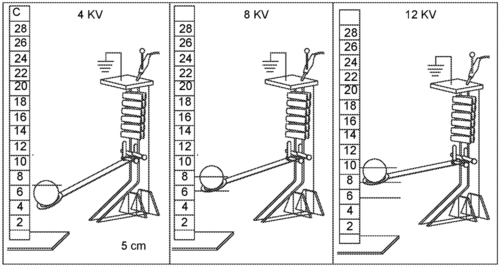
Keplinger, C. M., Acome, E. L., Kellaris, N. A., Mitchell, S. K.
Hydraulically Amplified Self-healing Electrostatic Actuators
(US Patent 11795979B2), October 2023 (patent)
hi
Mohan, M.
Gesture-Based Nonverbal Interaction for Exercise Robots
University of Tübingen, Tübingen, Germany, October 2023, Department of Computer Science (phdthesis)
rm
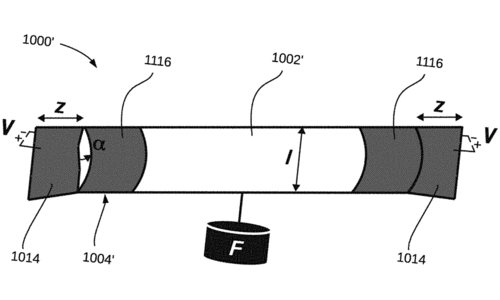
Keplinger, C. M., Wang, X., Mitchell, S. K.
High Strain Peano Hydraulically Amplified Self-Healing Electrostatic (HASEL) Transducers
(US Patent App. 18/138,621), August 2023 (patent)
ei
Karimi, A.
Advances in Algorithmic Recourse: Ensuring Causal Consistency, Fairness, & Robustness
ETH Zurich, Switzerland, July 2023 (phdthesis)
ei
Kübler, J. M.
Learning and Testing Powerful Hypotheses
University of Tübingen, Germany, July 2023 (phdthesis)
rm
Correll, N., Ly, K. D., Kellaris, N. A., Keplinger, C. M.
Capacitive Self-Sensing for Electrostatic Transducers with High Voltage Isolation
(US Patent App. 17/928,453), June 2023 (patent)
ei
Gresele, L.
Learning Identifiable Representations: Independent Influences and Multiple Views
University of Tübingen, Germany, June 2023 (phdthesis)
ei
Paulus, M.
Learning with and for discrete optimization
ETH Zurich, Switzerland, May 2023, CLS PhD Program (phdthesis)
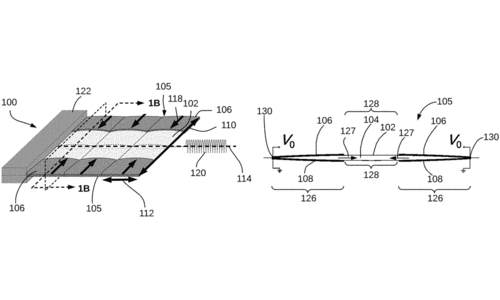
rm
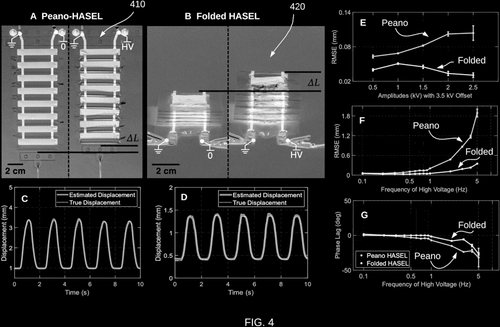
Keplinger, C. M., Wang, X., Mitchell, S. K.
High Strain Peano Hydraulically Amplified Self-healing Electrostatic (HASEL) Transducers
(US Patent 11635094), April 2023 (patent)
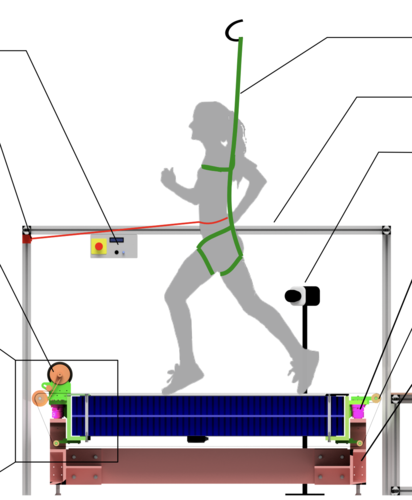
dlg
Sarvestani, A., Ruppert, F., Badri-Spröwitz, A.
An Open-Source Modular Treadmill for Dynamic Force Measurement with Load Dependant Range Adjustment
2023 (unpublished) Submitted
ei
Jin, Z., Mihalcea, R.
Natural Language Processing for Policymaking
In Handbook of Computational Social Science for Policy, pages: 141-162, 7, (Editors: Bertoni, E. and Fontana, M. and Gabrielli, L. and Signorelli, S. and Vespe, M.), Springer International Publishing, 2023 (inbook)
ev
Strecke, M. F.
Object-Level Dynamic Scene Reconstruction With Physical Plausibility From RGB-D Images
Eberhard Karls Universität Tübingen, Tübingen, 2023 (phdthesis)
pi
Wang, T., Hu, W., Sitti, M.
Tube-shaped robotic device with anisotropic surface structure
2023, US Patent App. 18/133,104 (patent)
pi
Drotlef, D., Sitti, M., Amjadi, M.
Carrier, use of a carrier, method of activating a carrier and method of making a carrier
2023, US Patent App. 16/500,442 (patent)
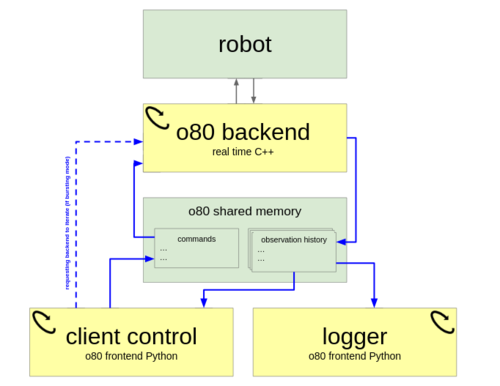
ei
Berenz, V., Widmaier, F., Guist, S., Schölkopf, B., Büchler, D.
Synchronizing Machine Learning Algorithms, Realtime Robotic Control and Simulated Environment with o80
Robot Software Architectures Workshop (RSA) 2023, ICRA, 2023 (techreport)
mms
Baluktsian, M.
Wave front shaping with zone plates: Fabrication and characterization of lenses for soft x-ray applications from standard to singular optics
Universität Stuttgart, Stuttgart (und Verlag Dr. Hut, München), 2023 (phdthesis)
mms
Bubeck, C.
Tailored perovskite-type oxynitride semiconductors and oxides with advanced physical properties
Technische Universität Darmstadt, Darmstadt, 2023 (phdthesis)
pi
Sitti, M., Aksak, B.
Microfibers with mushroom-shaped tips for optimal adhesion
2023, US Patent 11,613,674 (patent)
pi
Zhang, J., Ren, Z., Hu, W., Sitti, M.
Method of fabricating a magnetic deformable machine and deformable 3D magnetic machine
2023, US Patent App. 18/020,161 (patent)
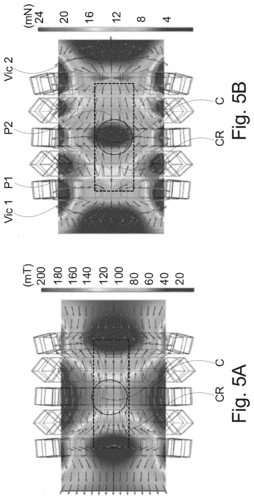
pi
Son, D., Ugurlu, M., Bluemer, P., Sitti, M.
Magnetic trap system and method of navigating a microscopic device
2023, US Patent App. 17/871,598 (patent)
pi
Sitti, M., Drotlef, D., Liimatainen, V.
A Liquid Repellent Fibrillar Dry Adhesive Material and a Method of Producing the Same
2023, US Patent App. 17/785,452 (patent)
pi
Sitti, M., Son, D., Dong, X.
Simultaneous calibration method for magnetic localization and actuation systems
2023, US Patent 11,717,142 (patent)
pi
M Sitti, M. M. B. A.
Dry adhesives and methods for making dry adhesives
2023, US Patent 11,773,298, 2023 (patent)
mms
Schulz, Frank Martin Ernst
Static and dynamic investigation of magnonic systems: materials, applications and modeling
Universität Stuttgart, Stuttgart, 2023 (phdthesis)
2022
pi
Metin Sitti, Michael Murphy, Burak Aksak
DRY ADHESIVES AND METHODS FOR MAKING DRY ADHESIVES
December 2022, US Patent App. 17/895,334, 2022 (patent)
hi
Richardson, B.
Multi-Timescale Representation Learning of Human and Robot Haptic Interactions
University of Stuttgart, Stuttgart, Germany, December 2022, Faculty of Computer Science, Electrical Engineering and Information Technology (phdthesis)

ps
Choutas, V.
Reconstructing Expressive 3D Humans from RGB Images
ETH Zurich, Max Planck Institute for Intelligent Systems and ETH Zurich, December 2022 (phdthesis)
dlg
Sarvestani, L. A.
Mechanical Design, Development and Testing of Bioinspired Legged Robots for Dynamic Locomotion
Eberhard Karls Universität Tübingen, Tübingen , November 2022 (phdthesis)
rm
Keplinger, C. M., Acome, E. L., Kellaris, N. A., Mitchell, S. K., Morrissey, T. G.
Hydraulically Amplified Self-healing Electrostatic Transducers Harnessing Zipping Mechanism
(US Patent 11486421B2), November 2022 (patent)
ei
Neitz, A.
Towards learning mechanistic models at the right level of abstraction
University of Tübingen, Germany, November 2022 (phdthesis)