
2025
ps
Gozlan, Y., Falisse, A., Uhlrich, S., Gatti, A., Black, M., Chaudhari, A.
OpenCapBench: A Benchmark to Bridge Pose Estimation and Biomechanics
In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , February 2025 (inproceedings)

2024
ps
Baert, K., Bharadwaj, S., Castan, F., Maujean, B., Christie, M., Abrevaya, V., Boukhayma, A.
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
In SIGGRAPH Asia 2024 Conference Proceedings, SIGGRAPH Asia 2024, December 2024 (inproceedings) Accepted

ei
Kapoor, J., Schulz, A., Vetter, J., Pei, F., Gao, R., Macke, J. H.
Latent Diffusion for Neural Spiking Data
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Didolkar, A. R., Goyal, A., Ke, N. R., Guo, S., Valko, M., Lillicrap, T. P., Rezende, D. J., Bengio, Y., Mozer, M. C., Arora, S.
Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Buchholz, S.
Learning partitions from Context
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
sf
Salaudeen, O., Hardt, M.
ImageNot: A Contrast with ImageNet Preserves Model Rankings
arXiv preprint arXiv:2404.02112, 2024 (conference) Submitted
sf
Nastl, V. Y., Hardt, M.
Predictors from Causal Features Do Not Generalize Better to New Domains
arXiv preprint arXiv:2402.09891, 2024 (conference) Submitted
ei
Garrido, S., Blöbaum, P., Schölkopf, B., Janzing, D.
Causal vs. Anticausal merging of predictors
In Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , 38th Annual Conference on Neural Information Processing Systems, December 2024 (inproceedings) Accepted
ei
Allingham, J. U., Mlodozeniec, B. K., Padhy, S., Antoran, J., Krueger, D., Turner, R. E., Nalisnick, E., Hernández-Lobato, J. M.
A Generative Model of Symmetry Transformations
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Rajendran*, G., Buchholz*, S., Aragam, B., Schölkopf, B., Ravikumar, P. K.
From Causal to Concept-Based Representation Learning
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Zhao, J., Singh, S. P., Lucchi, A.
Theoretical Characterisation of the Gauss Newton Conditioning in Neural Networks
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
sf
Mendler-Dünner, C., Carovano, G., Hardt, M.
An Engine Not a Camera: Measuring Performative Power of Online Search
arXiv preprint arXiv:2405.19073, 2024 (conference) Submitted
ei
Dmitriev, D., Buhai, R., Tiegel, S., Wolters, A., Novikov, G., Sanyal, A., Steurer, D., Yang, F.
Robust Mixture Learning when Outliers Overwhelm Small Groups
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Chen, W., Ge, H.
Neural Characteristic Activation Analysis and Geometric Parameterization for ReLU Networks
Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Lin, J. A., Padhy, S., Mlodozeniec, B. K., Antoran, J., Hernández-Lobato, J. M.
Improving Linear System Solvers for Hyperparameter Optimisation in Iterative Gaussian Processes
Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted

ps
Athanasiou, N., Cseke, A., Diomataris, M., Black, M. J., Varol, G.
MotionFix: Text-Driven 3D Human Motion Editing
In SIGGRAPH Asia 2024 Conference Proceedings, ACM, December 2024 (inproceedings) To be published
ei
Piatti*, G., Jin*, Z., Kleiman-Weiner*, M., Schölkopf, B., Sachan, M., Mihalcea, R.
Cooperate or Collapse: Emergence of Sustainability in a Society of LLM Agents
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024, *equal contribution (conference) Accepted
ei
Vetter, J., Moss, G., Schröder, C., Gao, R., Macke, J. H.
Sourcerer: Sample-based Maximum Entropy Source Distribution Estimation
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Jain, S., Lubana, E. S., Oksuz, K., Joy, T., Torr, P., Sanyal, A., Dokania, P. K.
What Makes Safety Fine-tuning Methods Safe? A Mechanistic Study
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
sf
Dominguez-Olmedo, R., Hardt, M., Mendler-Dünner, C.
Questioning the Survey Responses of Large Language Models
arXiv preprint arXiv:2306.07951, 2024 (conference) Submitted
sf
Dominguez-Olmedo, R., Dorner, F. E., Hardt, M.
Training on the Test Task Confounds Evaluation and Emergence
arXiv preprint arXiv:2407.07890, 2024 (conference) Submitted
ei
Chan, R., Bourmasmoud, R., Svete, A., Ren, Y., Guo, Q., Jin, Z., Ravfogel, S., Sachan, M., Schölkopf, B., El-Assady, M., Cotterell, R.
On Affine Homotopy between Language Encoders
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Pals, M., Sağtekin, A. E., Pei, F., Gloeckler, M., Macke, J.
Inferring stochastic low-rank recurrent neural networks from neural data
Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , 38th Annual Conference on Neural Information Processing Systems, December 2024 (conference) Accepted
ei
Guo, S., Zhang, C., Muhan, K., Huszár*, F., Schölkopf*, B.
Do Finetti: On Causal Effects for Exchangeable Data
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 38th Annual Conference on Neural Information Processing Systems, December 2024, *joint senior authors (conference) Accepted

ps
Zakharov, E., Sklyarova, V., Black, M. J., Nam, G., Thies, J., Hilliges, O.
Human Hair Reconstruction with Strand-Aligned 3D Gaussians
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)

ncs
ps
Ostrek, M., Thies, J.
Stable Video Portraits
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, European Conference on Computer Vision (ECCV 2024), October 2024 (inproceedings) Accepted

ps
Yi, H., Thies, J., Black, M. J., Peng, X. B., Rempe, D.
Generating Human Interaction Motions in Scenes with Text Control
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)

ps
Dakri, A., Arora, V., Challier, L., Keller, M., Black, M. J., Pujades, S.
On predicting 3D bone locations inside the human body
In 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), October 2024 (inproceedings)

ncs
ps
Ostrek, M., O’Sullivan, C., Black, M., Thies, J.
Synthesizing Environment-Specific People in Photographs
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, European Conference on Computer Vision (ECCV 2024), October 2024 (inproceedings) Accepted

ps
Feng, H., Ding, Z., Xia, Z., Niklaus, S., Fernandez Abrevaya, V., Black, M. J., Zhang, X.
Explorative Inbetweening of Time and Space
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)

ps
Tripathi, S., Taheri, O., Lassner, C., Black, M. J., Holden, D., Stoll, C.
HUMOS: Human Motion Model Conditioned on Body Shape
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, October 2024 (inproceedings)
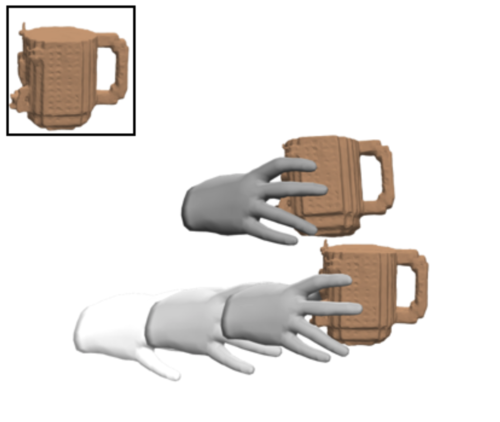
ps
Zhang, H., Christen, S., Fan, Z., Hilliges, O., Song, J.
GraspXL: Generating Grasping Motions for Diverse Objects at Scale
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, September 2024 (inproceedings) Accepted

ps
Sanyal, S.
Leveraging Unpaired Data for the Creation of Controllable Digital Humans
Max Planck Institute for Intelligent Systems and Eberhard Karls Universität Tübingen, September 2024 (phdthesis) To be published

ps
Osman, A. A. A.
Realistic Digital Human Characters: Challenges, Models and Algorithms
University of Tübingen, September 2024 (phdthesis)
ei
Schumacher, P., Krause, L., Schneider, J., Büchler, D., Martius, G., Haeufle, D.
Learning to Control Emulated Muscles in Real Robots: Towards Exploiting Bio-Inspired Actuator Morphology
In 10th International Conference on Biomedical Robotics and Biomechatronics (BioRob), September 2024 (inproceedings) Accepted

ps
Fan, Z., Ohkawa, T., Yang, L., Lin, N., Zhou, Z., Zhou, S., Liang, J., Gao, Z., Zhang, X., Zhang, X., Li, F., Zheng, L., Lu, F., Zeid, K. A., Leibe, B., On, J., Baek, S., Prakash, A., Gupta, S., He, K., Sato, Y., Hilliges, O., Chang, H. J., Yao, A.
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, September 2024 (inproceedings) Accepted

ps
Zuffi, S., Black, M. J.
AWOL: Analysis WithOut synthesis using Language
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, September 2024 (inproceedings)
ei
Immer, A.
Advances in Probabilistic Methods for Deep Learning
ETH Zurich, Switzerland, September 2024, CLS PhD Program (phdthesis)
ei
Schneider, F., Kamal, O., Jin, Z., Schölkopf, B.
Moûsai: Efficient Text-to-Music Diffusion Models
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Volume 1: Long Papers, pages: 8050-8068, (Editors: Lun-Wei Ku and Andre Martins and Vivek Srikumar), Association for Computational Linguistics, August 2024 (conference)
ei
Wu*, W., Chen*, W., Zhang, C., Woodland, P. C.
Modelling Variability in Human Annotator Simulation
Findings of the Association for Computational Linguistics (ACL), pages: 1139-1157, (Editors: Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek), Association for Computational Linguistics, August 2024, *equal contribution (conference)
ei
Ortu*, F., Jin*, Z., Doimo, D., Sachan, M., Cazzaniga, A., Schölkopf, B.
Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , Volume 1, Long Papers, pages: 8420-8436, (Editors: Lun-Wei Ku and Andre Martins and Vivek Srikumar), Association for Computational Linguistics, August 2024, *equal contribution (conference)
ei
Kumar, I., Jin, Z., Mokhtarian, E., Guo, S., Chen, Y., Kiyavash, N., Sachan, M., Schölkopf, B.
CausalCite: A Causal Formulation of Paper Citations
Findings of the Association for Computational Linguistics (ACL), pages: 8395-8410, (Editors: Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek), Association for Computational Linguistics, August 2024 (conference)
hi
Gong, Y.
Engineering and Evaluating Naturalistic Vibrotactile Feedback for Telerobotic Assembly
University of Stuttgart, Stuttgart, Germany, August 2024, Faculty of Design, Production Engineering and Automotive Engineering (phdthesis)
ei
Dmitriev, D., Szabó, K., Sanyal, A.
On the Growth of Mistakes in Differentially Private Online Learning: A Lower Bound Perspective
Proceedings of the 37th Annual Conference on Learning Theory (COLT), 247, pages: 1379-1398, Proceedings of Machine Learning Research, (Editors: Agrawal, Shipra and Roth, Aaron), PMLR, July 2024, (talk) (conference)
ei
Buchholz, S., Schölkopf, B.
Robustness of Nonlinear Representation Learning
Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 4785-4821, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (conference)
ei
Beck, J., Bosch, N., Deistler, M., Kadhim, K. L., Macke, J. H., Hennig, P., Berens, P.
Diffusion Tempering Improves Parameter Estimation with Probabilistic Integrators for ODEs
Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 3305-3326, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (conference)
ei
Schröder, C., Macke, J. H.
Simultaneous identification of models and parameters of scientific simulators
Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 43895-43927, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (conference)
al
Urpi, N. A., Bagatella, M., Vlastelica, M., Martius, G.
Causal Action Influence Aware Counterfactual Data Augmentation
In Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 1709-1729, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (inproceedings)
ei
robustml
Reizinger, P., Ujváry, S., Mészáros, A., Kerekes, A., Brendel, W., Huszár, F.
Position: Understanding LLMs Requires More Than Statistical Generalization
Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 42365-42390, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024 (conference)
ei
Chen*, W., Zhang*, M., Paige, B., Hernández-Lobato, J. M., Barber, D.
Diffusive Gibbs Sampling
Proceedings of the 41st International Conference on Machine Learning (ICML), 235, pages: 7731-7747, Proceedings of Machine Learning Research, (Editors: Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix), PMLR, July 2024, *equal contribution (conference)