
Chun-Hao Paul Huang
Alumni
Note: Chun-Hao Paul Huang has transitioned from the institute (alumni). Explore further information here
New! As of July 2022 I start at Adobe Research London as a research scientist.
This page will be maintained with lower update frequency. Check my new corporate webpage and personal website for the latest information.
I'm a postdoctoral researcher at Perceiving Systems department, Max-Planck-Institute for Intelligent Systems. My main research focus is on 3D visual perception from 2D images, such as 3D human body reconstruction, human-scene interaction, and marker-less motion capture, but I am also generally interested in any machine-learning or computer-vision challenge.
Prior to MPI-PS, I spent a year in industry and four wonderful Ph.D. years at TUM where I worked closely with PD. Dr. Slobodan Ilic, PD Dr. Federico Tombari and Prof. Dr. Nassir Navab. During the past few years, I also had the pleasure to work with: Dr. Edmond Boyer in team Morpheo, INRIA; MIX team in Microsoft Research Redmond; Capture and Effects team in Disney Research Zürich, and Dr. Yu-Chiang Frank Wang in team MML, Academia Sinica.
To know more about my former experience, here's my full CV and here's my personal website.
News:
- New! June 2023: MIME's website is up! Check out our code and data.
- New! June 2023: HumanCinemagraph's website is up!
- New! June 2023: IPMAN's website is up!
- New! March 2023: Four papers accepted at CVPR 2023! Stay tuned on: MIME, SGNify, IPMAN, and HumanCinemagraph.
- June 2022: RICH's website is up! Check out our code and data.
- June 2022: Our work "Accurate 3D Body Shape Regression using Metric and Semantic Attributes" is nominated as the best paper finalist in CVPR`22! 33 papers out of 8161 submissions!
- June 2022: SHAPY's website is up! Check out our code and data.
- June 2022: MOVER's website is up! Check out our code.
- June 2022: RICH's website is up! Check out our code and data.
- March 2022: Three papers accepted at CVPR 2022! Stay tuned on: RICH, SHAPY (oral), MOVER.
- Oct 2021: SPEC's website is up! Check out our code and data.
- Oct 2021: PARE's website is up and code released.
- July 2021: Two papers to appear in ICCV`21.
- June 2021: Our work "On Self-Contact and Human Pose" is nominated as the candidates for best-paper award in CVPR`21!
- March 2021: Two papers accepted to CVPR`21.
3D human pose and shape estimation; capture; registration; 3D computer vision
 HumanCinemagraph, CVPR 2023:
HumanCinemagraph, CVPR 2023:
 MIME, CVPR 2023:
MIME, CVPR 2023:
 SGNify, CVPR 2023:
SGNify, CVPR 2023:
data
 IPMAN, CVPR 2023:
IPMAN, CVPR 2023:
IPMAN code
 SmartMoCap, RAL 2023:
SmartMoCap, RAL 2023:
 RICH, CVPR 2022:
RICH, CVPR 2022:
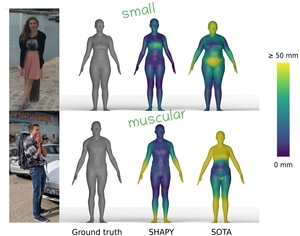 SHAPY, CVPR 2022:
SHAPY, CVPR 2022:
 MOVER, CVPR 2022:
MOVER, CVPR 2022:
 PARE, ICCV 2021:
PARE, ICCV 2021:
SPEC, ICCV 2021: 
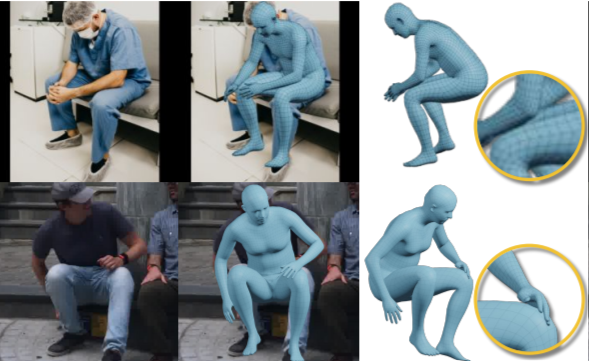
TUCH, CVPR 2021:
code: Self-contact lib, SMPLify-XMC, TUCH
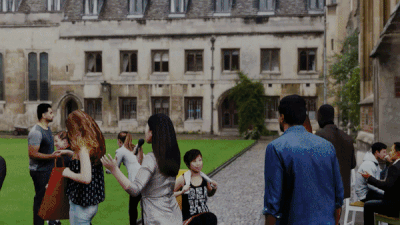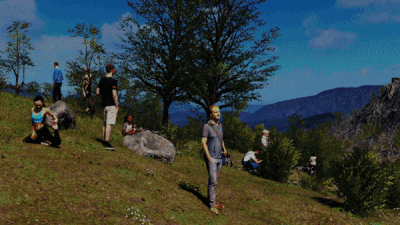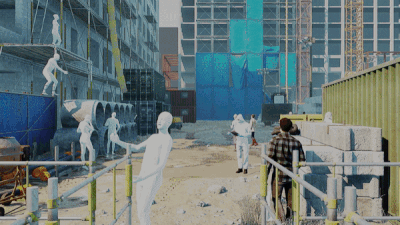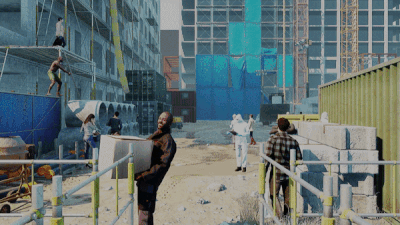
AGORA, CVPR 2021:
MIME: Human-Aware 3D Scene Generation
Generating realistic 3D worlds occupied by moving humans has many applications in games, architecture, and synthetic data creation. But generating such scenes is expensive and labor intensive. Recent work generates human poses and motions given a 3D scene. Here, we take the opposite approach and generate 3D indoor scenes given 3D human motion. Such motions can come from archival motion capture or from IMU sensors worn on the body, effectively turning human movement in a “scanner” of the 3D world. Intuitively, human movement indicates the free-space in a room and human contact indicates surfaces or objects that support activities such as sitting, lying or touching. We propose MIME (Mining Interaction and Movement to infer 3D Environments), which is a generative model of indoor scenes that produces furniture layouts that are consistent with the human movement. MIME uses an auto-regressive transformer architecture that takes the already generated objects in the scene as well as the human motion as input, and outputs the next plausible object. To train MIME, we build a dataset by populating the 3D FRONT scene dataset with 3D humans. Our experiments show that MIME produces more diverse and plausible 3D scenes than a recent generative scene method that does not know about human movement.
IPMAN: 3D Human Pose Estimation via Intuitive Physics
The estimation of 3D human body shape and pose from images has advanced rapidly. While the results are often well aligned with image features in the camera view, the 3D pose is often physically implausible; bodies lean, float, or penetrate the floor. This is because most methods ignore the fact that bodies are typically supported by the scene. To address this, some methods exploit physics engines to enforce physical plausibility. Such methods, however, are not differentiable, rely on unrealistic proxy bodies, and are difficult to integrate into existing optimization and learning frameworks. To account for this, we take a different approach that exploits novel intuitive-physics (IP) terms that can be inferred from a 3D SMPL body interacting with the scene. Specifically, we infer biomechanically relevant features such as the pressure heatmap of the body on the floor, the Center of Pressure (CoP) from the heatmap, and the SMPL body’s Center of Mass (CoM) projected on the floor. With these, we develop IPMAN, to estimate a 3D body from a color image in a “stable” configuration by encouraging plausible floor contact and overlapping CoP and CoM. Our IP terms are intuitive, easy to implement, fast to compute, and can be integrated into any SMPL-based optimization or regression method; we show examples of both. To evaluate our method, we present MoYo, a dataset with synchronized multi-view color images and 3D bodies with complex poses, body-floor contact, and ground-truth CoM and pressure. Evaluation on MoYo, RICH and Human3.6M show that our IP terms produce more plausible results than the state of the art; they improve accuracy for static poses, while not hurting dynamic ones. Code and data will be available for research.
Reconstructing Signing Avatars From Video Using Linguistic Priors
Sign language (SL) is the primary method of communication for the 70 million Deaf people around the world. Video dictionaries of isolated signs are a core SL learning tool. Replacing these with 3D avatars can aid learning and enable AR/VR applications, improving access to technology and online media. However, little work has attempted to estimate expressive 3D avatars from SL video. This task is difficult due to occlusion, noise, and motion blur. We address this by introducing novel linguistic priors that are universally applicable to SL and provide constraints on 3D hand pose that help resolve ambiguities within isolated signs. Our method, SGNify, captures fine-grained hand pose, facial expression, and body movement fully automatically from in-the-wild monocular SL videos. We evaluate SGNify quantitatively by using a commercial motion-capture system to compute 3D avatars synchronized with monocular video. SGNify outperforms state-of-the-art 3D body-pose- and shape-estimation methods on SL videos. A perceptual study shows that SGNify’s 3D reconstructions are significantly more comprehensible and natural than those of previous methods and are on par with the source videos.
SmartMocap: Joint Estimation of Human and Camera Motion using Uncalibrated RGB Cameras
Markerless human motion capture (mocap) from multiple RGB cameras is a widely studied problem. Existing methods either need calibrated cameras or calibrate them relative to a static camera, which acts as the reference frame for the mocap system. The calibration step has to be done a priori for every capture session, which is a tedious process, and re-calibration is required whenever cameras are intentionally or accidentally moved. In this paper, we propose a mocap method which uses multiple static and moving extrinsically uncalibrated RGB cameras. The key components of our method are as follows. First, since the cameras and the subject can move freely, we select the ground plane as a common reference to represent both the body and the camera motions unlike existing methods which represent bodies in the camera coordinate. Second, we learn a probability distribution of short human motion sequences (~1sec) relative to the ground plane and leverage it to disambiguate between the camera and human motion. Third, we use this distribution as a motion prior in a novel multi-stage optimization approach to fit the SMPL human body model and the camera poses to the human body keypoints on the images. Finally, we show that our method can work on a variety of datasets ranging from aerial cameras to smartphones. It also gives more accurate results compared to the state-of-the-art on the task of monocular human mocap with a static camera. Our code is available at https://github.com/robot-perception-group/SmartMocap.
RICH & BSTRO: Capturing and Inferring Dense Full-Body Human-Scene Contact
Inferring human-scene contact (HSC) is the first step toward understanding how humans interact with their surroundings. While detecting 2D human-object interaction (HOI) and reconstructing 3D human pose and shape (HPS) have enjoyed significant progress, reasoning about 3D human-scene contact from a single image is still challenging. Existing HSC detection methods consider only a few types of predefined contact, often reduce body and scene to a small number of primitives, and even overlook image evidence. To predict human-scene contact from a single image, we address the limitations above from both data and algorithmic perspectives. We capture a new dataset called RICH for “Real scenes, Interaction, Contact and Humans.” RICH contains multiview outdoor/indoor video sequences at 4K resolution, ground-truth 3D human bodies captured using markerless motion capture, 3D body scans, and high resolution 3D scene scans. A key feature of RICH is that it also contains accurate vertex-level contact labels on the body. Using RICH, we train a network that predicts dense body-scene contacts from a single RGB image. Our key insight is that regions in contact are always occluded so the network needs the ability to explore the whole image for evidence. We use a transformer to learn such non-local relationships and propose a new Body-Scene contact TRansfOrmer (BSTRO). Very few methods explore 3D contact; those that do focus on the feet only, detect foot contact as a post-processing step, or infer contact from body pose without looking at the scene. To our knowledge, BSTRO is the first method to directly estimate 3D body-scene contact from a single image. We demonstrate that BSTRO significantly outperforms the prior art. The code and dataset are available at https://rich.is.tue.mpg.de.
MOVER: Human-Aware Object Placement for Visual Environment Reconstruction
Humans are in constant contact with the world as they move through it and interact with it. This contact is a vital source of information for understanding 3D humans, 3D scenes, and the interactions between them. In fact, we demonstrate that these human-scene interactions (HSIs) can be leveraged to improve the 3D reconstruction of a scene from a monocular RGB video. Our key idea is that, as a person moves through a scene and interacts with it, we accumulate HSIs across multiple input images, and optimize the 3D scene to reconstruct a consistent, physically plausible and functional 3D scene layout. Our optimization-based approach exploits three types of HSI constraints: (1) humans that move in a scene are occluded or occlude objects, thus, defining the depth ordering of the objects, (2) humans move through free space and do not interpenetrate objects, (3) when humans and objects are in contact, the contact surfaces occupy the same place in space. Using these constraints in an optimization formulation across all observations, we significantly improve the 3D scene layout reconstruction. Furthermore, we show that our scene reconstruction can be used to refine the initial 3D human pose and shape (HPS) estimation. We evaluate the 3D scene layout reconstruction and HPS estimation qualitatively and quantitatively using the PROX and PiGraphs datasets. The code and data are available for research purposes at https://mover.is.tue.mpg.de/
PARE: Part Attention Regressor for 3D Human Body Estimation
Despite significant progress, state of the art 3D human pose and shape estimation methods remain sensitive to partial occlusion and can produce dramatically wrong predictions although much of the body is observable. To address this, we introduce a soft attention mechanism, called the Part Attention REgressor (PARE), that learns to predict body-part-guided attention masks. We observe that state-of-the-art methods rely on global feature representations, making them sensitive to even small occlusions. In contrast, PARE's part-guided attention mechanism overcomes these issues by exploiting information about the visibility of individual body parts while leveraging information from neighboring body-parts to predict occluded parts. We show qualitatively that PARE learns sensible attention masks, and quantitative evaluation confirms that PARE achieves more accurate and robust reconstruction results than existing approaches on both occlusion-specific and standard benchmarks. The code and data are available for research purposes at https://pare.is.tue.mpg.de/
SPEC: Seeing People in the Wild with an Estimated Camera
Due to the lack of camera parameter information for in-the-wild images, existing 3D human pose and shape (HPS) estimation methods make several simplifying assumptions: weak-perspective projection, large constant focal length, and zero camera rotation. These assumptions often do not hold and we show, quantitatively and qualitatively, that they cause errors in the reconstructed 3D shape and pose. To address this, we introduce SPEC, the first in-the-wild 3D HPS method that estimates the perspective camera from a single image and employs this to reconstruct 3D human bodies more accurately. First, we train a neural network to estimate the field of view, camera pitch, and roll given an input image. We employ novel losses that improve the calibration accuracy over previous work. We then train a novel network that concatenates the camera calibration to the image features and uses these together to regress 3D body shape and pose. SPEC is more accurate than the prior art on the standard benchmark (3DPW) as well as two new datasets with more challenging camera views and varying focal lengths. Specifically, we create a new photorealistic synthetic dataset (SPEC-SYN) with ground truth 3D bodies and a novel in-the-wild dataset (SPEC-MTP) with calibration and high-quality reference bodies. Both qualitative and quantitative analysis confirm that knowing camera parameters during inference regresses better human bodies.
TUCH - Towards Understanding Contact in Humans
People touch their face 23 times an hour, they cross their arms and legs, put their hands on their hips, etc. While many images of people contain some form of self-contact, current 3D human pose and shape (HPS) regression methods typically fail to estimate this contact. To address this, we develop new datasets and methods that significantly improve human pose estimation with self-contact. First, we create a dataset of 3D Contact Poses (3DCP) containing SMPL-X bodies fit to 3D scans as well as poses from AMASS, which we refine to ensure good contact. Second, we leverage this to create the Mimic-The-Pose (MTP) dataset of images, collected via Amazon Mechanical Turk, containing people mimicking the 3DCP poses with self- contact. Third, we develop a novel HPS optimization method, SMPLify-XMC, that includes contact constraints and uses the known 3DCP body pose during fitting to create near ground-truth poses for MTP images. Fourth, for more image variety, we label a dataset of in-the-wild images with Discrete Self-Contact (DSC) information and use another new optimization method, SMPLify-DC, that exploits discrete contacts during pose optimization. Finally, we use our datasets during SPIN training to learn a new 3D human pose regressor, called TUCH (Towards Under- standing Contact in Humans). We show that the new self-contact training data significantly improves 3D human pose estimates on withheld test data and existing datasets like 3DPW. Not only does our method improve results for self-contact poses, but it also improves accuracy for non-contact poses. The code and data are available for research purposes at https://tuch.is.tue.mpg.de.