Multi-Modal Scene Understanding for Robotic Grasping
2011
Ph.D. Thesis
am
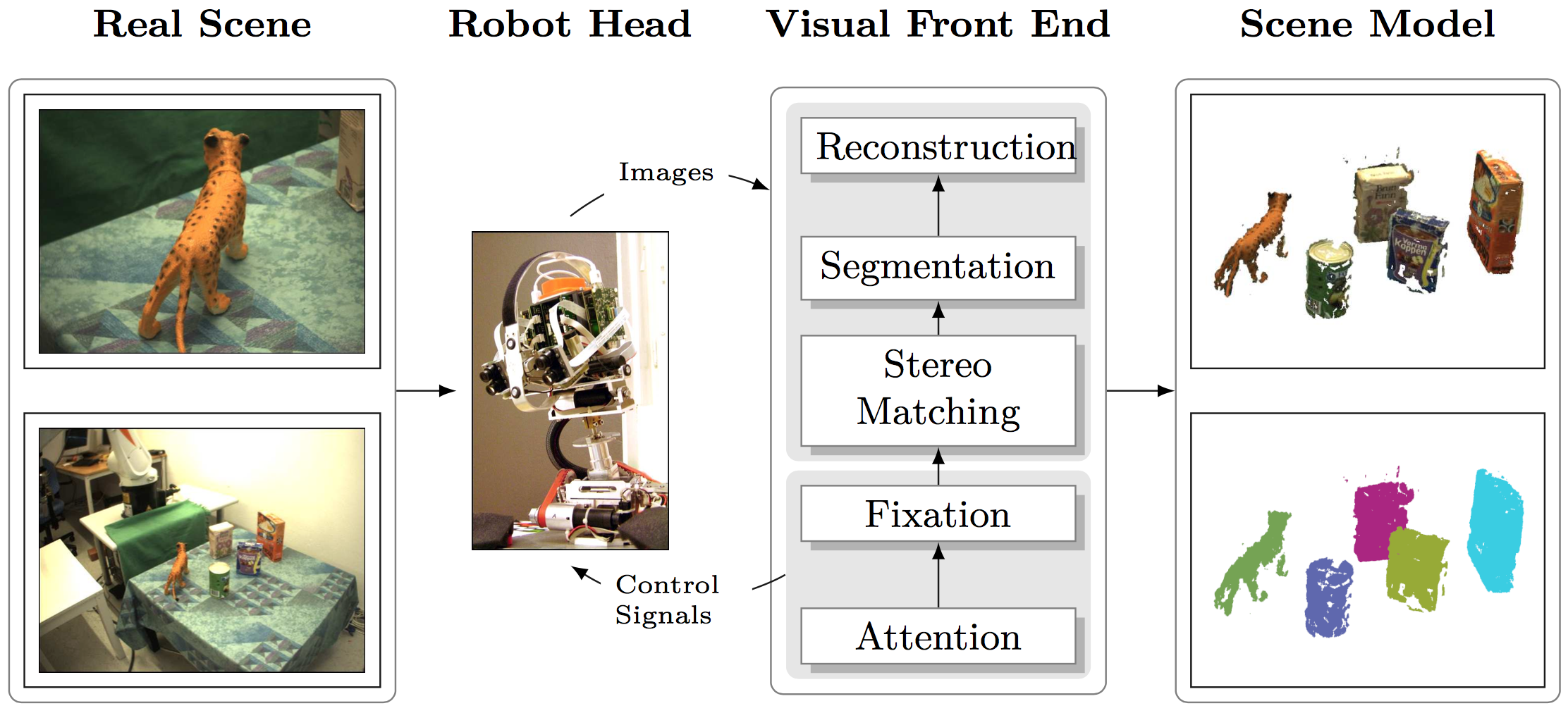
Current robotics research is largely driven by the vision of creating an intelligent being that can perform dangerous, difficult or unpopular tasks. These can for example be exploring the surface of planet mars or the bottom of the ocean, maintaining a furnace or assembling a car. They can also be more mundane such as cleaning an apartment or fetching groceries. This vision has been pursued since the 1960s when the first robots were built. Some of the tasks mentioned above, especially those in industrial manufacturing, are already frequently performed by robots. Others are still completely out of reach. Especially, household robots are far away from being deployable as general purpose devices. Although advancements have been made in this research area, robots are not yet able to perform household chores robustly in unstructured and open-ended environments given unexpected events and uncertainty in perception and execution.In this thesis, we are analyzing which perceptual and motor capabilities are necessary for the robot to perform common tasks in a household scenario. In that context, an essential capability is to understand the scene that the robot has to interact with. This involves separating objects from the background but also from each other.Once this is achieved, many other tasks become much easier. Configuration of object scan be determined; they can be identified or categorized; their pose can be estimated; free and occupied space in the environment can be outlined.This kind of scene model can then inform grasp planning algorithms to finally pick up objects.However, scene understanding is not a trivial problem and even state-of-the-art methods may fail. Given an incomplete, noisy and potentially erroneously segmented scene model, the questions remain how suitable grasps can be planned and how they can be executed robustly.In this thesis, we propose to equip the robot with a set of prediction mechanisms that allow it to hypothesize about parts of the scene it has not yet observed. Additionally, the robot can also quantify how uncertain it is about this prediction allowing it to plan actions for exploring the scene at specifically uncertain places. We consider multiple modalities including monocular and stereo vision, haptic sensing and information obtained through a human-robot dialog system. We also study several scene representations of different complexity and their applicability to a grasping scenario. Given an improved scene model from this multi-modal exploration, grasps can be inferred for each object hypothesis. Dependent on whether the objects are known, familiar or unknown, different methodologies for grasp inference apply. In this thesis, we propose novel methods for each of these cases. Furthermore,we demonstrate the execution of these grasp both in a closed and open-loop manner showing the effectiveness of the proposed methods in real-world scenarios.
| Author(s): | Bohg, Jeannette |
| Number (issue): | 2011:17 |
| Pages: | vi, 194 |
| Year: | 2011 |
| Month: | December |
| Series: | Trita-CSC-A |
| Publisher: | KTH Royal Institute of Technology |
| Department(s): | Autonomous Motion |
| Bibtex Type: | Ph.D. Thesis (phdthesis) |
| School: | KTH, Computer Vision and Active Perception, CVAP, Centre for Autonomous Systems, CAS |
| Institution: | KTH, Centre for Autonomous Systems, CAS |
| ISBN: | 978-91-7501-184-4 |
| Links: |
pdf
|
|
BibTex @phdthesis{Bohg459199,
title = {Multi-Modal Scene Understanding for Robotic Grasping},
author = {Bohg, Jeannette},
number = {2011:17},
pages = {vi, 194},
series = {Trita-CSC-A},
publisher = {KTH Royal Institute of Technology},
institution = {KTH, Centre for Autonomous Systems, CAS},
school = {KTH, Computer Vision and Active Perception, CVAP, Centre for Autonomous Systems, CAS},
month = dec,
year = {2011},
doi = {},
month_numeric = {12}
}
|
|